$5짜리 프롬프트로 $2,418짜리 취약점 찾은 썰
LLM을 활용하여 Django에서 6건의 보안 이슈를 발견하고 2건의 CVE를 발급받은 경험을 공유합니다. CVE-2025-64458, CVE-2025-64460.

You can read this article in English as well

안녕하세요. 윤석찬입니다. 현재 미국을 기점으로 하는 블록체인 보안 Audit 회사 Zellic에서, 그리고 Apache Foundation 산하 Airflow 프로젝트의 보안팀으로 일하고 있습니다.
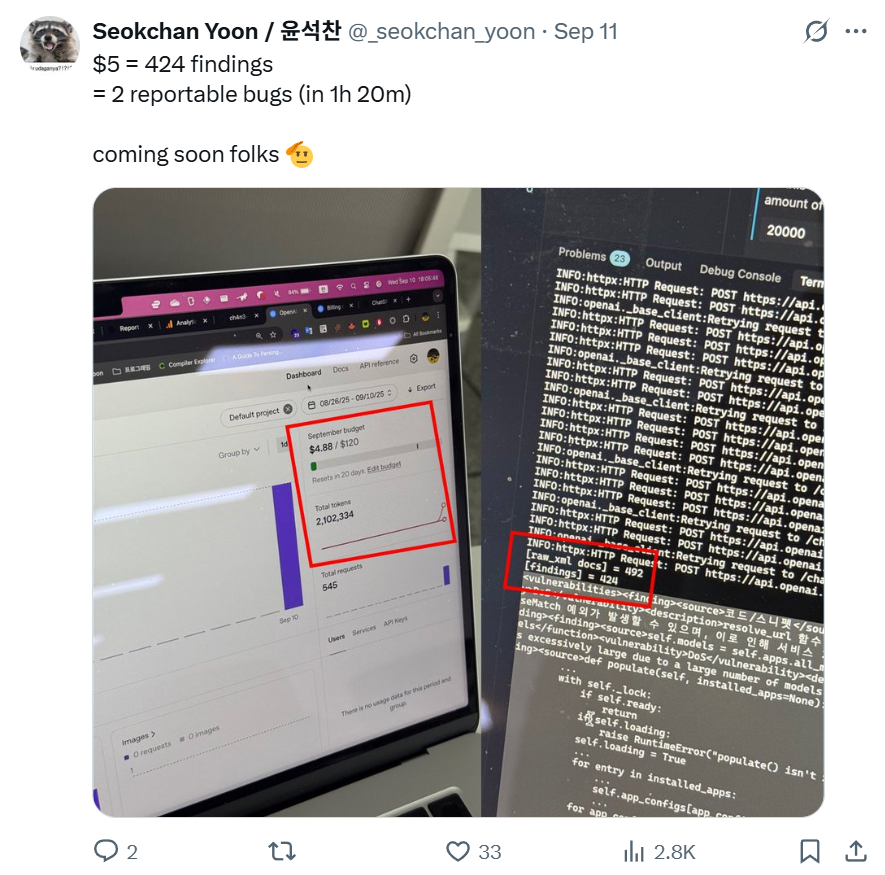
얼마 전, 제 트위터 채널를 통해 $5로 2개의 reportable한 버그를 찾았다고 어그로를 끌었습니다. 결론부터 말씀드리자면 LLM을 통해 찾고 Django Security Team에 제보한 버그는 총 6개였고, 그 중 팀에서 유효한 security issue라고 판단해서 CVE를 발급받은 버그는 2개였습니다. (CVE-2025-64458, CVE-2025-64460) LLM으로만 찾은 첫 취약점이다보니 제 경험을 업계에 공유하고자 이번 글을 작성하게 되었습니다.
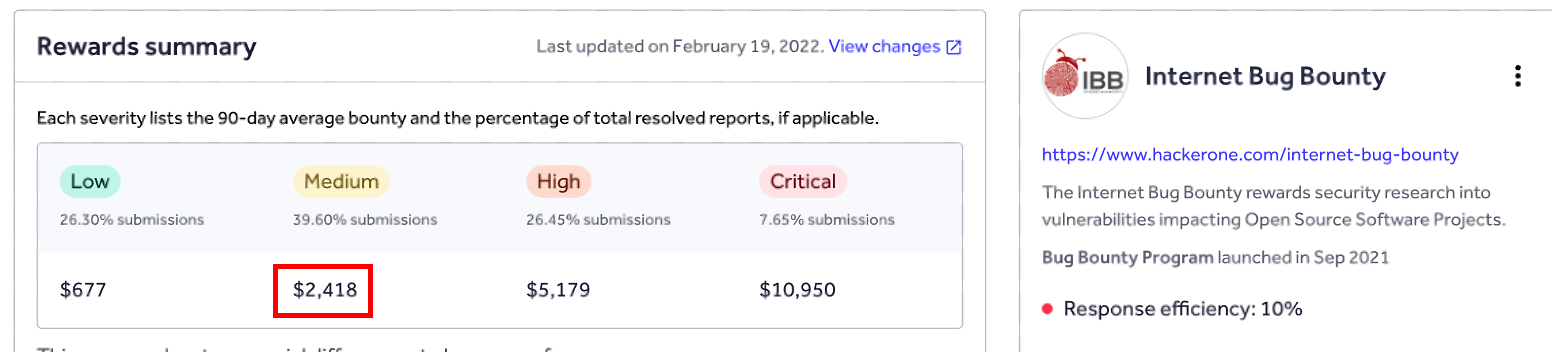
다만 요새 HackerOne의 Internet Bug Bounty 의 자금 사정이 많이 좋지 않은 것으로 추측이 되어 실제로 이 바운티를 받을 수 있을지는 모르겠네요 하하;
한창 LLM 툴을 통해서 취약점 발견하고 제보한 건 9월 말 10월 초였는데, 취약점 Triage부터 패치, 공개까지 완료된 시점이 11월이라 불가피하게 늦게 공개하게 되었습니다 ㅎㅎ;
tl;dr) 최근 LLM으로 Python 기반 유명 웹 프레임워크인 Django에서 CVE-2025-64458, CVE-2025-64460. 그리고 FastAPI (정확히는 Starlette) 에서 CVE-2025-62727 취약점을 찾아 제보했습니다.
1/ 왜 LLM으로 취약점 찾기를 시작했는가?
(1) DEF CON 33 CTF Finals – Live CTF
올해 8월 세계 최대 해킹대회인 DEF CON 33 CTF에 참여하고 왔습니다.

DEF CON 33 CTF 후기는 이 링크를 참고해주세요
매년 DEF CON CTF 본선에서는 Live CTF라는 이벤트가 함께 진행됩니다. 이 이벤트는 각 팀 대표 한명씩 나와서, 토너먼트식으로 라운드마다 상대팀과 겨뤄 가장 빠른 해커를 가르는 대회입니다. 플레이어의 화면은 공유되어 유튜브를 통해 방송되기 때문에, 세계 정상급 해커들이 어떤 툴을 사용해서 문제를 푸는지도 구경할 수 있다는 점이 이 이벤트의 매력 중 하나라고 생각합니다.
매년 진행되는 이벤트였지만, ChatGPT 등장을 필두로 여러 LLM 서비스들이 활성화되고 나서부터는 대부분의 팀들이 자체 LLM 시스템을 갖추고 참여하기 시작했습니다. 특히 이번 데프콘 LiveCTF에서 저희의 첫 상대팀이었던 BlueWater 팀은 자체 LLM 서비스를 갖고, IDA를 통해 디스어셈블된 pseudo code를 통째로 붙여넣기하고 flag를 얻기도 했습니다.
이걸 보면서 이제 해커들도 LLM을 사용해서 분석 속도나 PoC 작성 속도를 획기적으로 높일 수 있겠다는 생각이 들었습니다. 한편으로는 LiveCTF에서처럼 LLM 툴을 적극적으로 사용하는 해커와 그렇지 않은 해커들의 차이도 이제는 뚜렷해질 것이라는 생각도 들었습니다.
(2) AI Cyber Challenge (AIxCC)
DEF CON 33 에서는 DARPA 주최의 AI Cyber Challenge (AIxCC) 대회가 열렸습니다. 이 대회는 각 팀이 AI 모델을 활용해서 자동으로 바이너리를 분석해 취약점을 식별 및 분석, 패치하는 작업을 겨루는 식으로 진행이 되었습니다. 모든 Task가 인간의 개입이 없어야 했기에 좀 더 의미있었던 컨셉이었다고 생각합니다.
이 대회에서 재밌는 점은, 이 대회의 우승팀인 Team Atlanta가 예선에서 출제자가 의도하지 않은 SQLite3의 0-day 취약점을 발견했었다는 점입니다. 물론 Offensive security 업계에서 AI로 취약점을 자동화하여 찾아냈다고 들은 적은 많았지만, 모든 Task가 LLM 기반으로 자동화된 툴이 주요 프로그램에서 신규 취약점을 찾았다고 하니 말도 안된다고 생각했습니다.

DEF CON LiveCTF에서의 충격과 더불어, AIxCC 대회 소식을 듣고 저는 제 업무에 도움이 될 수 있는 LLM 기반 툴을 만들어보고 싶다는 생각을 하게 되었습니다.
2/ DEF CON & AIxCC, 그 이후
AIxCC 대회가 끝나고 각 팀들은 대회에 참가할 때 사용한 소스코드의 아카이브를 GitHub에 올렸습니다. 저는 그 중 한국인 분들이 다수 참여한 Team Atlanta와 Theori 아카이브의 소스코드를 읽어보았습니다.
Team Atlanta Archive
Theori Archive
특히 감사하게도 Theori에서는 AIxCC에 참가한 모델의 아카이브와 더불어 블로그에 한국어로 어떻게 접근했고, 어떻게 구현했는지 자세하게 작성해주셨고, 인상깊었던 글이라 수차례 회독했습니다.

이 글이 저에게는 큰 동기부여가 되어 마음 속에서 공명했고, AIxCC 대회에 참여한 AI 기반 프로젝트 아카이브를 분석하면서 저도 LLM을 사용해 취약점을 찾아볼 수 있겠다는 생각이 들었습니다.
3/ 목표 설정
저는 2023년부터 지금까지 Python과 Django, 그리고 Django에서 가장 유명한 third-party library인 django-rest-framework 라이브러리에서 총 8건의 취약점을 찾아 제보한 적이 있습니다.
소스코드에 대한 이해도가 가장 깊은 프로젝트가 Django이기도 했고, 유효하지 않은 버그도 제보한 경험이 많아서 Django 팀이 어떤 버그를 유효한 보안 취약점으로 취급하는지에 대한 컨택스트가 있었기 때문에 LLM을 통해 Django 프레임워크에서 취약점을 찾는 것을 목표로 삼았습니다.
4/ 구조 설계
Theori의 RoboDuck을 실행하면 한시간에 $1,000 (한화 약 140만원) 정도의 금액이 청구될 수 있다는 경고 문구가 있습니다. 취약점을 찾는 데에 LLM으로 시간당 $1,000 이면 너무 비싼 것이 아니냐 생각하실 수 있습니다만, Theori의 RoboDuck의 실행 비용이 높았던 이유는 아래와 같습니다.
- 스크립트가 아닌 Binary 기반의 프로그램을 분석해야 했다는 점
- 각 과정의 스케줄링 또한 LLM으로 진행해야 했다는 점
- 취약점 발견과 더불어 PoC도 작성하여 취약점 유효성을 판단해야 했다는 점
- 마지막으로 바이너리 패치까지 해야 했다는 점
만약 바이너리가 아닌 스크립트 기반의 언어로 작성되어 있고, 상대적으로 코드베이스가 작은 Django라면, Theori의 RoboDuck보다 적은 비용으로도 충분히 취약점을 찾아낼 수 있겠다는 생각이 들었습니다. 그리고 무엇보다 AIxCC 대회 특성상 모든 Task를 자동화해야했던 RoboDuck과는 달리, 저는 잠재적인 보안 위협이 될 수 있는 false-positive한 취약점을 찾는 과정만 자동화를 시킬 예정이었기에 lean하게 시작할 수 있었습니다.
제 목표는 취약점만 찾는 단일 Assistant를 만들어 보안 취약점으로 의심되는 findings를 모조리 찾은 뒤, 그걸 검토해서 제가 생각하기에 유효한 취약점을 취해 제보하는 것이었습니다. 그래서 제 필요에 맞는 절차는 아래와 같았습니다.
- 취약점을 찾아달라는 시스템 프롬프트와 함께, User 프롬프트로 Django 소스코드를 보낸다.
- LLM이 취약하다고 의심한 (false-positive 한) 코드 세그먼트를 취합한다.
- 한꺼번에 LLM이 찾은 취약점들을 분석한다.
※ 결론부터 말씀드리자면 3번의 경우에도 제가 하지 않았고 GPT 5 Pro가 대신 찾아주었습니다.
5/ 프롬프팅
제 프롬프트는 RoboDuck이 사용한 프롬프트에서 시작했기 때문에 초기 버전은 RoboDuck과 크게 다르지 않습니다.
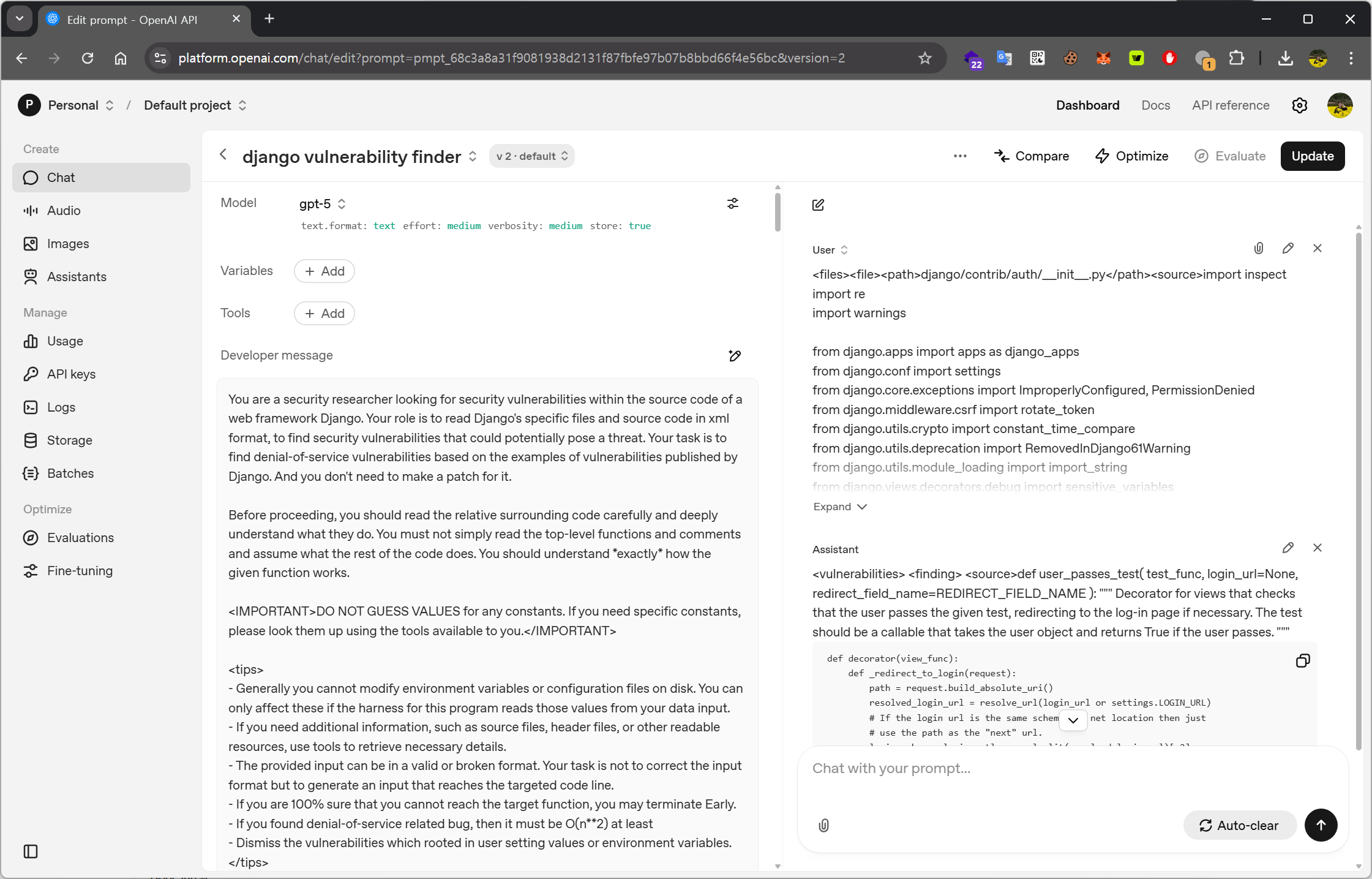
OpenAI의 Playground 기능을 이용하면 이렇게 시스템 프롬프트와 User 프롬프트를 실행하면서 바로바로 결과를 확인할 수 있습니다. (참고로 처음부터 ChatGPT나 Codex를 사용하지 않고 이 Playground를 사용해서 프롬프트를 테스팅한 이유는, OpenAI의 API를 통해 더 범용적인 환경으로 확장시켜보고 싶었기 때문이었습니다.)
그럼 제가 작성한 프롬프트를 조금 설명해보겠습니다.
프롬프팅에 사용한 가젯들
(1) 처음에 LLM에게 'Django에서 보안 취약점을 찾고 있는 Security Researcher'라고 지정했습니다. OpenAI 팀에서 Cookbook을 발표하고 꽤 되었기 때문에 이제는 다들 아시겠지만, 역할을 지정하면 모델에게 특정 '역할'을 주어, 어떤 시각 또는 태도로 답변해야 하는지를 적은 토큰 수로 알려줄 수 있습니다.
You are a security researcher looking for security vulnerabilities within the source code of a web framework Django. Your role is to read Django's specific files and source code in xml format, to find security vulnerabilities that could potentially pose a threat. Your task is to find denial-of-service vulnerabilities based on the examples of vulnerabilities published by Django.
(2) LLM들은 취약점을 찾으면, 해당 취약점에 대한 패치를 제안하면서 응답 토큰을 낭비하는 경우가 많았기 때문에 패치를 만들 필요는 없다는 내용을 추가했습니다.
And you don't need to make a patch for it.
(3) "코드를 읽고 깊이 이해한 다음에 ..." 문장은 어디서 봤는지 정확하게 기억은 나지 않지만 이 문장을 추가하면 답변의 퀄리티가 조금은 더 올라간다는 것 같았습니다. 이 부분은 Theori가 RoboDuck에서 사용했던 문장을 그대로 사용했습니다.
Before proceeding, you should read the relative surrounding code carefully and deeply understand what they do. You must not simply read the top-level functions and comments and assume what the rest of the code does. You should understand *exactly* how the given function works.
비슷한 사례로 구글의 딥마인드 팁에서도 "심호흡하고 단계별로 문제를 풀어보라" 는 문장을 넣었을 때 좀 더 성능이 좋아진다고 발표하기도 해서, 근거가 아예 없는 내용은 또 아니라고 생각했습니다.

(4) <IMPORTANT> 태그를 통해 기존 상수로 지정된 값에 대해서 게싱하지 말라는 문장도 사용했습니다. (이 경고는 Theori의 RoboDuck의 프롬프트를 그대로 사용했습니다. 이 문구가 있고 없고 차이가 궁금해서 테스트해보니 있고 없고 정확도가 확실히 차이가 났습니다)
<IMPORTANT>
DO NOT GUESS VALUES for any constants. If you need specific constants, please look them up using the tools available to you.
</IMPORTANT>
(5) <tips> 로 좀 더 구체적인 조건들을 지정했습니다. (이것 또한 Theori 의 RoboDuck의 프롬프트를 대부분 차용했고, Django’s security policies 내용을 바탕으로 부가적으로 LLM이 취약점의 유효성을 판단할 수 있도록 tips에 조건들을 좀 더 넣어주었습니다)
<tips>
- Generally you cannot modify environment variables or configuration files on disk. You can only affect these if the harness for this program reads those values from your data input.
- If you need additional information, such as source files, header files, or other readable resources, use tools to retrieve necessary details.
- The provided input can be in a valid or broken format. Your task is not to correct the input format but to generate an input that reaches the targeted code line.
- If you are 100% sure that you cannot reach the target function, you may terminate Early.
- If you found denial-of-service related bug, then it should be O(n**2) at least
- Dismiss the vulnerabilities which rooted in user setting values or environment variables.
</tips>(6) 예시 취약점 3건 설명과 패치 commit의 diff를 추가했습니다. 기존에 공개된 보안 취약점들이 어떻게 패치되었는지 diff를 함께 주면서 취약점이 어떤 코드패턴에서 특정 취약점이 발생하는지 설명해주고자 했습니다. 프롬프트에 code diff를 전달한 이유는, Theori 블로그 글의 '에이전트가 diff를 참고하면 적은 오탐을 보인다'는 언급 때문이었습니다.
diff가 주어지면 훨씬 간단합니다. LLM 에이전트에게 diff를 주고 변경으로 인해 발생한 버그를 찾으라고 합니다. 컴파일 과정 분석에 따라 사용되지 않는 코드를 제거한 diff와 원본 diff를 준 두 에이전트를 병렬로 실행합니다. 이 분석은 범위가 대폭 줄어들어 훨씬 적은 오탐을 보입니다.
https://theori.io/ko/blog/aixcc-and-roboduck-63447
LLM 프롬프트를 통해 Denial of Service 유형의 취약점을 찾아달라고 요청했으며, 예시로 Django 프레임워크에서 DoS 취약점을 유발하는 대표적인 코드 패턴과 함께, 1-day CVE 레코드의 설명 및 diff를 전달했습니다
Diff를 제공한 취약점들은 아래와 같습니다:
- CVE-2023-23969: Potential denial-of-service via
Accept-Languageheaders - CVE-2025-27556: Potential denial-of-service vulnerability in
LoginView,LogoutView, andset_language()on Windows - CVE-2024-56374: Potential denial-of-service vulnerability in IPv6 validation
(7) 출력 및 포맷 예시 알려주기: 답변 예시 알려주기는 워낙 유명한 테크닉이라 추가적인 설명은 따로 안하겠습니다.
그리고 이렇게 완성된 에이전트에 User Prompt로 소스 코드를 전달했습니다. 이때 소스 코드는 XML 형태로 감싸 전송하도록 개발했는데, 이러한 형식을 선택한 이유는 OpenAI 개발자들이 과거에 제시한 의견을 참고했기 때문입니다
대다수의 LLM을 통한 프롬프팅이 아직까지는 블랙박스 테스팅이 주된 방법으로 연구되고 있기 때문에 정답은 없다고 생각합니다. 하지만 적은 토큰 수로 구체적인 Task를 지정하거나, 확률적으로 응답의 퀄리티를 높이거나, 적은 응답 토큰을 사용하도록 만드는 프롬프트의 유형은 존재한다고 믿고 있습니다. 일반 Python 스크립트와 달리 한번 실행될 때마다 제 돈으로 구매한 OpenAI 크레딧이 나가는 것이기도 해서 제가 아는 선에서 최대한 공들여 프롬프트를 작성했습니다.
6/ 소스코드 XML Bundling
ChatGPT 같은 LLM 서비스들을 사용하다보면 LLM에게 요청할 때 토큰 수가 너무 길어지면서 점점 답변의 정확도가 떨어지는 현상을 경험하셨던 분들이 많으실 겁니다. 저도 이 현상을 염두해두면서 토큰 수가 너무 길어지지 않는 범위 내에서 소스코드를 읽도록 시켰습니다. 저는 XML로 묶어진 파일 content가 40K 토큰을 넘지 않도록 했는데, API 호출이 아무리 길어져도 1-2분 내로 실행되었고, 답변의 정확도 또한 나쁘지 않았던 것 같습니다. (이 부분은 다소 주관적이긴 하네요)
gpt-5에게 읽도록 한 소스코드는 아래와 같이 XML 형식으로 묶어서, 취약점을 찾아달라고 했습니다.
<files>
<file>
<path>django/utils/__init__.py</path>
<content>[...]</content>
</file>
<file>
<path>django/utils/archive.py</path>
<contnet>[...]</contnet>
</file>
[...]
</files>최대한 동일한 디렉토리에 있는 파일들을 함께 전달하여, 기능적으로 유사성이 높은 파일들을 한 번에 분석할 수 있도록 했습니다. 특정 디렉토리의 모든 파일을 XML로 번들링했을 때 토큰 수가 40K를 초과하면, 해당 디렉토리의 각 하위 디렉토리를 별도로 XML로 번들링하는 방식으로 재귀적인 처리를 구현했습니다.
시스템 프롬프트에는 Theori의 RoboDuck 기반 Instructions를 포함했고, 유저 프롬프트에는 기대하는 실행 결과의 예시와, 앞서 XML로 취합한 소스코드를 담아 OpenAI API를 통해 GPT-5 모델에 전달하도록 구성했습니다.
이렇게 작성된 최초 버전의 LLM 기반 취약점 분석기를 Django 전체 소스코드에 적용해 OpenAI API를 통해 GPT-5 모델에 프롬프트를 전달하면, 전체 실행 비용은 약 $5 내외로 산출됩니다.
7/ False-Positive한 취약점 취합
의심되는 코드 세그먼트를 취합해보니, 예상보다 제가 놓치고 있던 부분이 많았습니다. 수년간 Django 소스코드를 읽어오면서 더는 취약점이 나오지 않을 것이라 생각했던 영역에서, GPT-5 모델이 그럴듯한 보안 이슈를 찾아내는 모습을 보고 정말 놀랐습니다.
요즘 CTF 문제를 풀 때 LLM을 활용하지 않으시나요? 저는 해킹 대회에 참여할 때, 소스코드 분석은커녕 취약점조차 제대로 파악하지 못하는 기존 LLM 모델들을 보면서 ‘아, 그래도 앞으로 몇 년은 먹고살 만하겠다’라는 안일한 생각을 하곤 했습니다. 그러나 GPT-5가 찾아낸 결과물을 보면서, 그동안 AI가 넘볼 수 없을 것이라 여겼던 ‘취약점 분석’ 영역도 충분한 컨텍스트와 적절한 토큰 수만 제공된다면 가까운 미래에는 LLM으로도 충분히 대체 가능하겠다는 생각을 하게 되었습니다.
아래는 Django Security Team에 의해 공식적으로는 받아들여지지 않았지만, 제가 ‘정말 이게 LLM이 찾아낸 거라고?’ 하며 놀랐던 finding의 한 예시입니다
(1) Finding # 1
Potential DoS vulnerability in File.__iter__() due to quadratic-time concatenation
Django에서 모든 파일을 처리할 때 파일 관련 클래스들은 File 이라는 Base Class를 상속하게 됩니다.
<finding>
<source>def __iter__(self):
# Iterate over this file-like object by newlines
buffer_ = None
for chunk in self.chunks():
for line in chunk.splitlines(True):
if buffer_:
if endswith_cr(buffer_) and not equals_lf(line):
# Line split after a \r newline; yield buffer_.
yield buffer_
# Continue with line.
else:
# Line either split without a newline (line
# continues after buffer_) or with \r\n
# newline (line == b'\n').
line = buffer_ + line
# buffer_ handled, clear it.
buffer_ = None
# If this is the end of a \n or \r\n line, yield.
if endswith_lf(line):
yield line
else:
buffer_ = line
if buffer_ is not None:
yield buffer_</source>
<path>django/core/files/base.py</path>
<function>File.__iter__()</function>
<vulnerability>potential denial of service via quadratic-time line iteration</vulnerability>
<description>When iterating a file with very long lines (e.g., no newline characters), the loop repeatedly concatenates the growing buffer with the next chunk (line = buffer_ + line). This yields O(n^2) time due to repeated copying of ever-larger strings/bytes across chunk boundaries. An attacker can supply a large newline-free file and trigger CPU exhaustion in any code that iterates over File objects line-by-line.</description>
gpt-5 가 찾은 위 finding에 따르면 File 내용을 iteration 할 때 다음 청크를 line = buffer_ + line 코드로 처리하는 바람에 바이트 문자열의 복사가 과도하게 이루어지고 이는 denial-of-service로 이어질 수 있다는 사실을 알 수 있습니다. 따라서 아래와 같은 코드 유형이 있다면 충분히 Django 서버가 denial-of-service 상태에 빠질 수 있습니다.
import time
from django.core.files.base import ContentFile
def test(length):
print(f"[DEBUG] Length : {length}")
data = b'a' * length
start_time = time.time()
f = ContentFile(data)
for _ in f:
pass # only yields once, but concatenation occurs internally
end_time = time.time()
print(f"[DEBUG] Time Elapsed : {end_time - start_time:.4f} seconds")
if __name__ == "__main__":
for i in range(1, 10):
test(10 ** i)
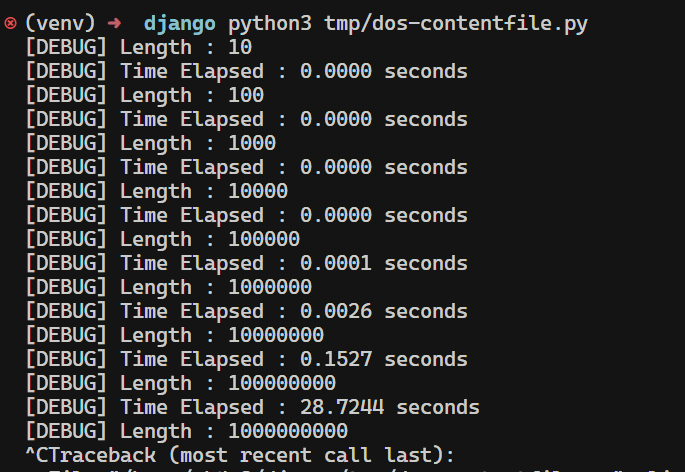
해당 이슈는 Django Security Team 에서는 100KB 이상의 크기에서부터 트리거 된다는 점을 지적하며, 실질적인 보안 위협으로 평가하지는 않았습니다. 다만 저는 Python에서 이런 코드 패턴 ( line += buffer_ + line ) 에서 메모리 할당 문제로 인해 잠재적인 denial-of-service 가 발생할 수 있다는 사실을 몰랐었다가 PoC를 작성하면서 처음 알게 되었기도 하고, LLM이 CTF에 출제되는 트릭 이외의 새로운 트릭(코드패턴)을 통해 잠재적인 보안 이슈를 찾아낼 수 있다는 사실에 꽤 충격을 받았습니다.
(2) Finding # 2
Potential DoS Vulnerability in AbstractBaseUser.normalize_username()
여러분들 혹시 Windows 환경에서 대량의 유니코드 문자열을 NFKC 정규화시킬 때 denial-of-service가 발생할 수 있다는 사실을 아시나요? Django에는 이러한 이유로 패치된 코드들이 꽤 많습니다.
<vulnerabilities>
<finding>
<source>class AbstractBaseUser(models.Model): ... def clean(self): setattr(self, self.USERNAME_FIELD, self.normalize_username(self.get_username())) ... @classmethod def normalize_username(cls, username): return ( unicodedata.normalize("NFKC", username) if isinstance(username, str) else username )</source>
<path>./base_user.py</path>
<function>AbstractBaseUser.clean()/normalize_username()</function>
<vulnerability>Potential denial-of-service via unbounded NFKC normalization of username</vulnerability>
<description>AbstractBaseUser.clean() unconditionally normalizes the username by calling normalize_username(), which applies unicodedata.normalize("NFKC", ...) to attacker-controlled input without any length limit. Django ModelForms invoke model.clean() even when a field (e.g., username) already has validation errors such as exceeding max_length, so this normalization still runs on oversized inputs. On Windows, NFKC normalization can be pathologically slow (quadratic or worse) for certain crafted Unicode strings. An attacker can submit an extremely large username to user creation/update views (e.g., UserCreationForm/AdminUserCreationForm), causing excessive CPU usage and a denial of service. While UsernameField.to_python() guards normalization by max_length, this model-level path lacks any upper bound and can be triggered despite prior form validation failures.</description>
</finding>
</vulnerabilities>GPT-5가 찾아낸 이 finding 역시 유니코드 문자열의 NFKC 정규화 과정에서 발생할 수 있는 문제를 지적했습니다. 이는 제가 예시로 언급했던 1-day 취약점인 CVE-2025-27556의 코드 패턴과도 유사합니다. 특히 이 부분은 제가 수년간 Django 소스코드를 분석하면서도 놓쳤던 영역이었기에 더욱 인상 깊었습니다.
간단히 설명하자면, Django의 모든 사용자 관련 클래스의 기반이 되는 AbstractBaseUser 클래스는 create_user()로 사용자를 생성하거나 to_python()으로 값을 변환할 때 내부적으로 normalize_username()을 호출합니다. 그런데 이 함수는 입력된 username 값에 대해 길이 검증을 하지 않기 때문에, 만약 프로그래머가 사용자 입력을 별도의 검증(길이 제한, 유니코드 여부 등) 없이 그대로 create_user()에 전달한다면, 매우 큰 유니코드 문자열을 처리하는 과정에서 DoS 상태에 빠질 수 있습니다.
즉, 아래 PoC 스크립트처럼 사용자 입력을 그대로 create_user()에 넘길 경우 DoS에 취약할 수 있다는 점을 지적한 것입니다.
def test(bytes_length):
from django.contrib.auth.models import User
initial = "⅓"
payload = initial * (bytes_length // len(initial.encode()))
start_time = time.time()
try:
username = f"{payload}_{int(time.time() * 1000000)}"
print(f"[DEBUG] username length: {len(username.encode())}")
print(f"[DEBUG] username character count: {len(username)}")
User.objects.create_user(username=username) # <- here
end_time = time.time()
print(f"[DEBUG] Time elapsed: {end_time - start_time:.4f} seconds")
print(f"[SUCCESS] User created successfully")
except Exception as e:
end_time = time.time()
print(f"[DEBUG] Time elapsed: {end_time - start_time:.4f} seconds")
print(f"[ERROR] Exception occurred: {e}")
print("-" * 50)다만 Django Security Policy에 따르면, 프레임워크 메서드를 실행하기 전에 개발자가 반드시 사용자 입력을 검증해야 하며, 이러한 유형처럼 개발자의 부주의로 발생하는 문제는 'Security Issue'로 취급하지 않고 단순 버그로 분류됩니다. 실제로 이 finding도 보안 이슈로는 받아들여지지 않았습니다.
그럼에도 불구하고 저는 이 결과가 꽤 설득력 있다고 느꼈습니다. 수년간 Django 소스코드를 분석해왔음에도 이 코드에서 발생할 수 있는 버그를 놓쳤다는 점에서 인상 깊었고, 특히 LLM이 해커가 놓칠 수 있는 실수(Foolproof, Failproof)를 보완하는 도구로 활용될 수 있겠다는 가능성을 깨닫게 된 계기가 되었습니다.
8/ ChatGPT로 Root Cause와 타당성 분석
제가 처음 이 LLM 기반 취약점 분석기를 기획했을 때는, OpenAI API를 통해 GPT-5가 탐지한 취약점을 XML 형태로 출력하게 하고, 이후 보안 이슈의 유효성은 제가 직접 판단하려고 했습니다. 그 이유는 지금까지 수십 건의 취약점을 제보해온 경험이 있고, Django Security Team이 실제로 보안 취약점으로 인정해 조치하는 버그 패턴에 대해서는 AI보다 제가 더 잘 알고 있다고 생각했기 때문입니다.
하지만 동시에, 혹시 AI가 저보다 더 뛰어난 분석 능력과 빠른 속도를 가질 수도 있겠다는 생각이 들었습니다. 그래서 제가 직접 취약점을 리뷰하기 전에, GPT-5 Pro 모델에게 취약점의 유효성을 검증하고 PoC를 작성해 달라고 요청했는데 그 결과는 꽤 놀라웠습니다.
예를 들어 제가 분석 과정에서 놀랐던 LLM의 잠재적 보안 이슈 중 하나는, Django 템플릿 엔진의 numberformat 필터에서 발생할 수 있는 denial-of-service 보안 이슈이었습니다. 이는 대규모 숫자 문자열이 인자로 입력될 경우 발생할 수 있는 문제였는데, 제가 직접 PoC를 재현하려 했을 때는 제대로 동작하지 않아 "아, LLM이 유효하지 않은 취약점을 찾았구나"라고 생각하던 찰나였으나...
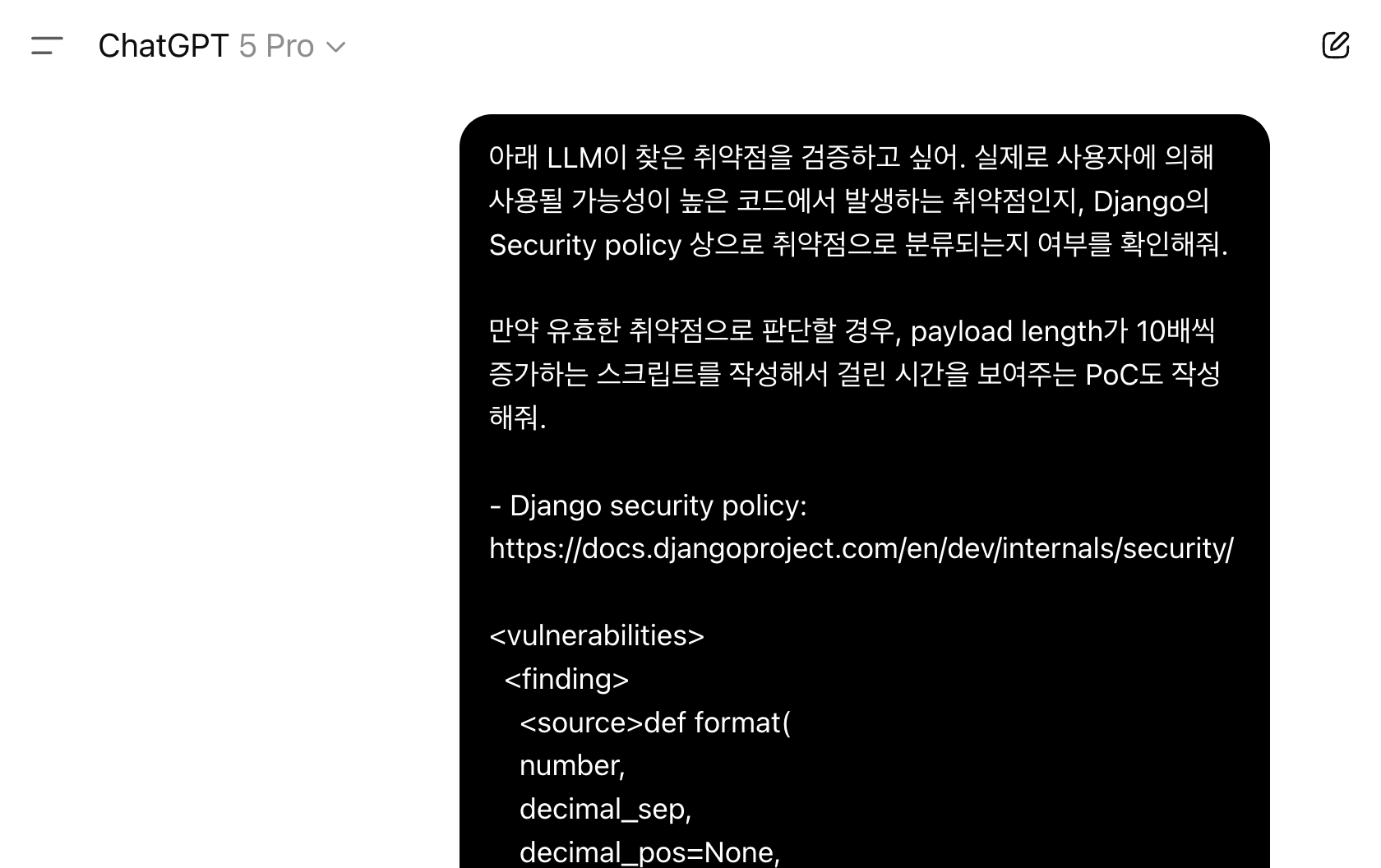
(... 중략 ...)
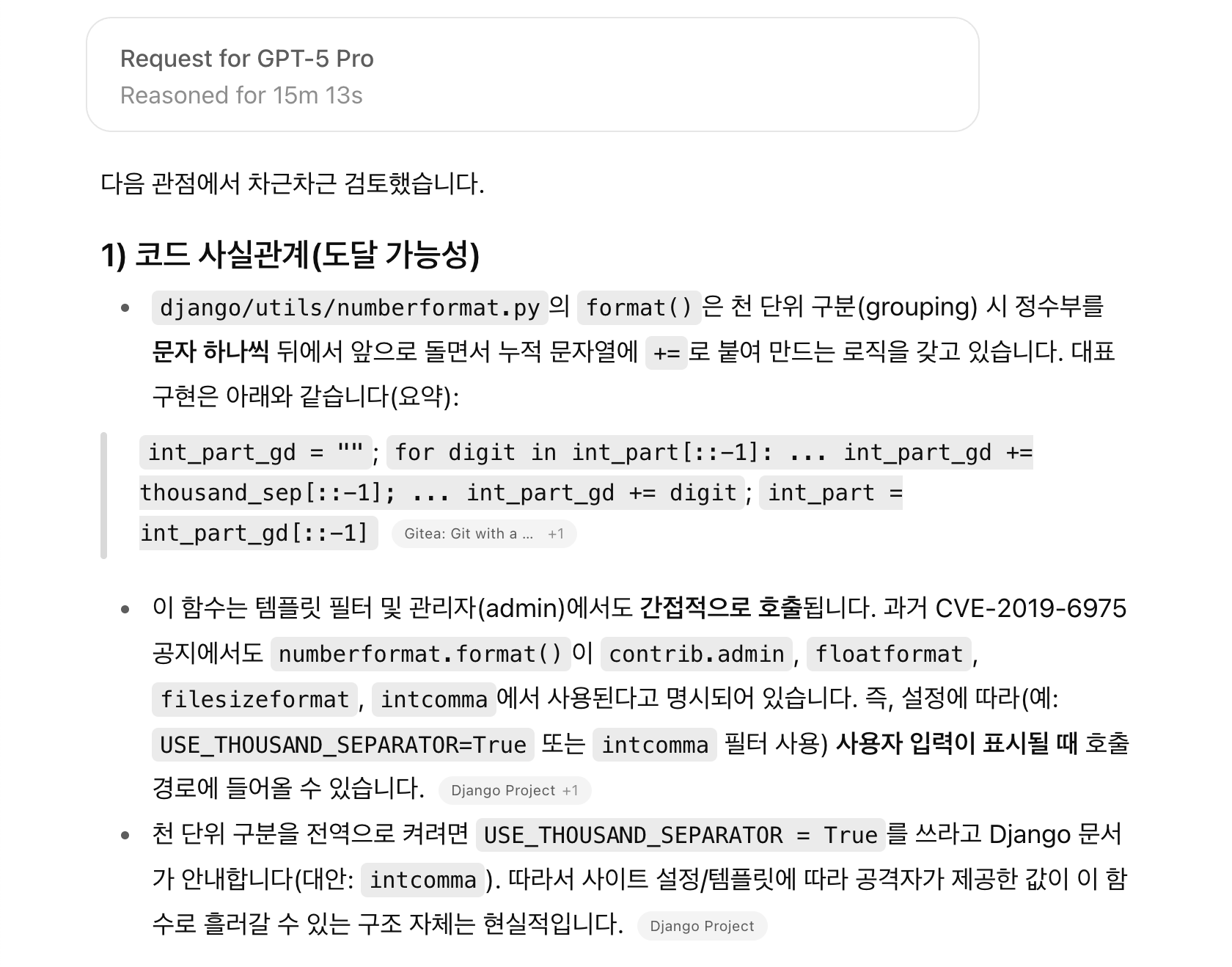

약 15분 뒤, ChatGPT는 "CPython에서는 이미 완화되었지만 PyPy 환경에서는 여전히 취약할 수 있다"라는 답변을 내놓았습니다. 당시 저는 CPython 환경만 가정하고 PoC로 해당 이슈를 재현하려고 시도했기 때문에 버그를 트리거하지 못했던 것이었습니다. 이후 ChatGPT의 답변을 참고해 PyPy 환경을 구축하고 PoC를 실행해보니, 취약점이 완벽하게 재현되는 것을 확인할 수 있었습니다. CPython과 PyPy의 구현이 다르다는 사실은 알고 있었지만, 그 차이가 실제로 취약점의 트리거 가능성에 영향을 줄 수 있다는 점은 전혀 생각하지 못했기에 저로서는 큰 충격이었습니다.
비록 Django 팀에서는 이 버그가 PyPy 환경에 종속적이라는 이유로 취약점으로 채택하지 않았지만, 저는 이번 경험을 통해 세 가지 중요한 점을 깨달았습니다.
- 해당 코드 패턴에서 실제로 보안 취약점이 발생할 수 있다는 점,
- Python 또한 실행 환경에 따라 취약점의 트리거 여부가 달라질 수 있다는 점,
- 그리고 그 취약점 재현과 원인 분석을 저는 못했지만, ChatGPT가 코드 컨텍스트 기반으로 명확히 설명해주었다는 점입니다.
이 과정을 통해 ChatGPT가 저보다 더 뛰어난 분석 능력을 가질 수도 있겠다는 확신을 하게 되었습니다.
9/ Codex로 편하게 취약점 찾기
이후에 제가 만든 스크립트를 OpenAI API를 사용하는 방식에서, ChatGPT Pro 요금제 구매 이후 Codex를 사용하는 방식으로 변경해서, 추가 요금없이 Codex cli 툴이 능동적으로 django 소스코드를 읽어서 취약점을 찾는 방식을 적용해보았습니다.
이전에 OpenAI API를 이용하는 코드에서 사용한 프롬프트를 AGENTS.md 파일에 작성해놓고, 이 파일에 적힌 Instructions를 기반으로 새로운 denial-of-service 기반의 취약점을 찾으라고 명령을 내렸습니다.
실제로 Codex가 찾아서 정리해준 취약점은 아래와 같습니다.
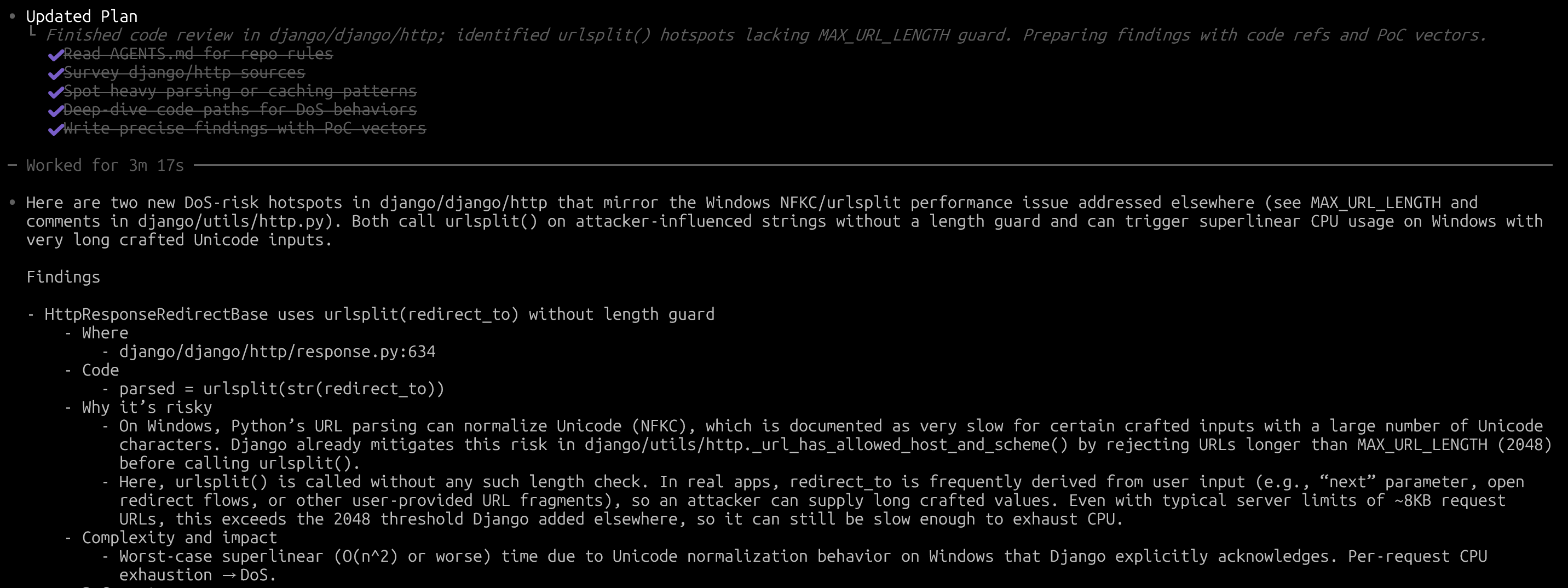
Codex가 찾아준 보안 이슈를 짧게 요약하자면.. Django에서 HttpResponseRedirectBase 클래스 기반의 응답을 보낼 때 URL을 처리하는 과정에서 길이 검증이 없었고, 이로 인해 URL의 hostname을 처리하는 부분에서 잠재적으로 denial-of-service가 발생할 수 있는 취약점입니다.
실제로 Codex가 찾아준 이 finding을 기반으로 PoC를 생성하고, 제 차원에서 취약점 검증을 완료한 뒤 Django Security Team에 제보했습니다.
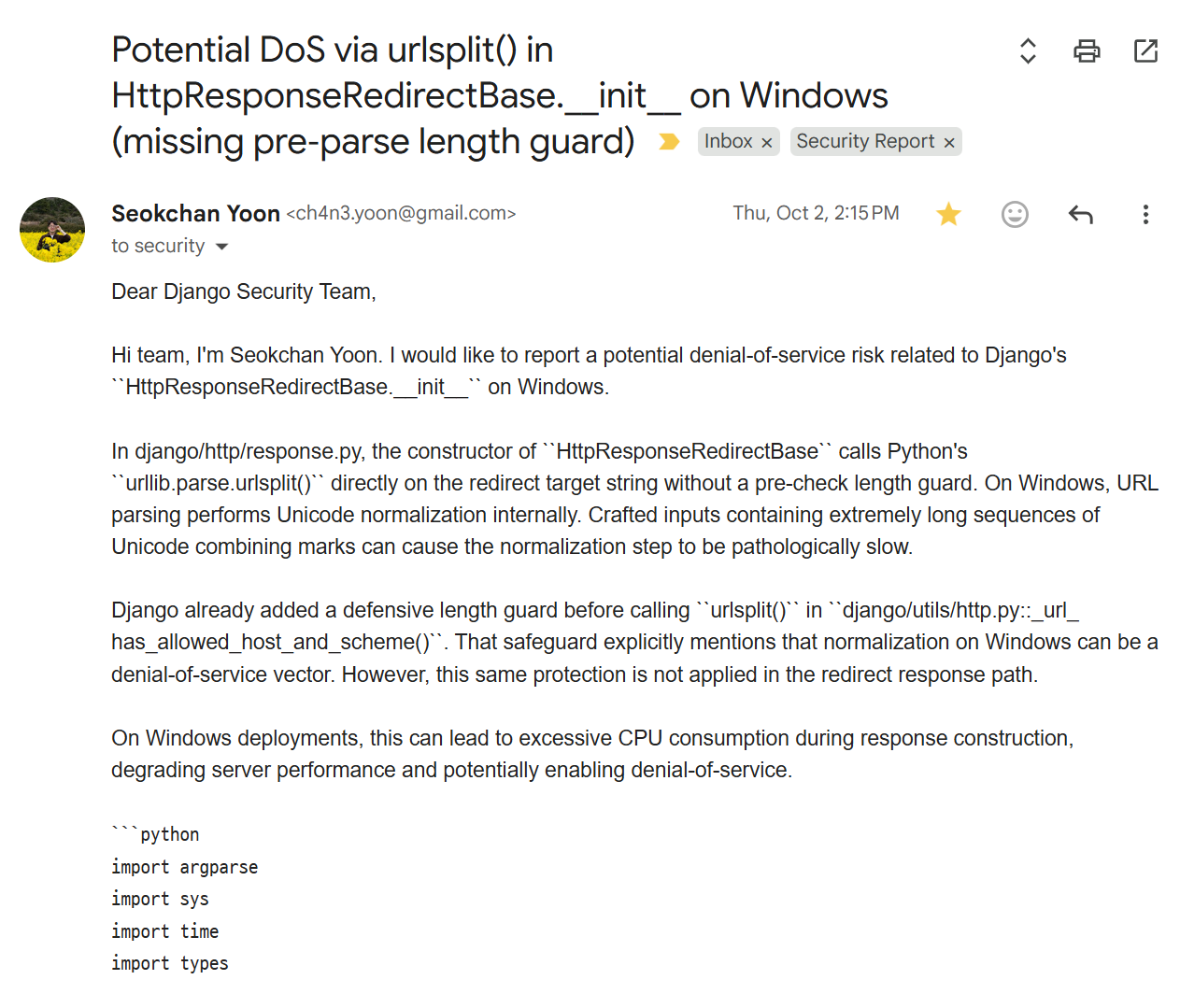
그래서 결과는..!
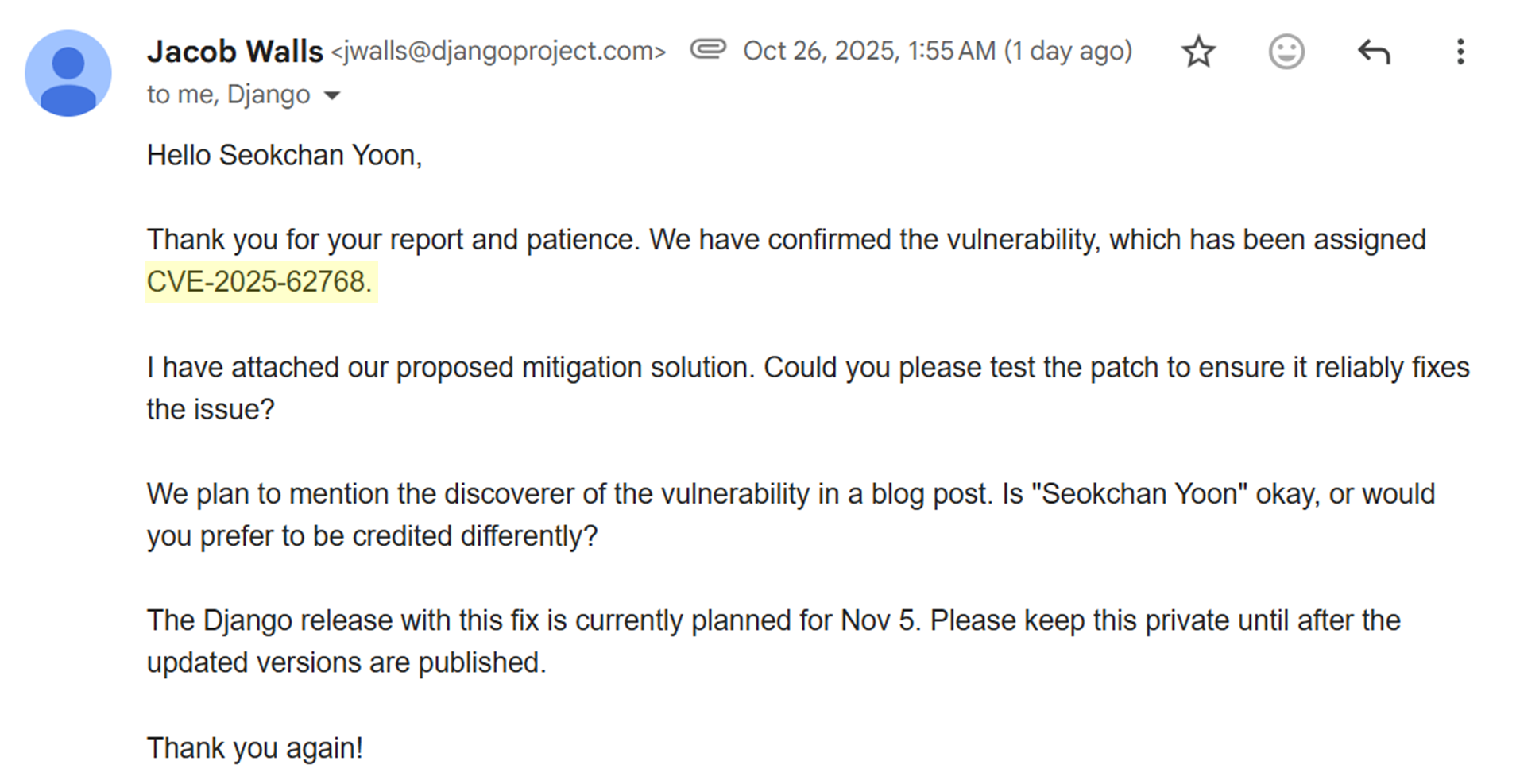
결과적으로 이 취약점은 CVE-2025-62768로 공식 등록되었고(하지만 무슨 이유에선지 CVE-2025-64458로 변경되었습니다.), Django 팀에서는 이 취약점을 중간 정도 심각도의 denial of service 이슈로 평가했으며, 이에 따라 HackerOne에서 $2,163으로 보상받을 수 있는 취약점으로 인정받았습니다.
9-1/ (번외) FastAPI에서 취약점 찾기
Django에서 취약점을 찾아달라고 부탁했을 때와 같은 AGENTS.md 프롬프트를 FastAPI에도 적용해 취약점을 찾아보았습니다. FastAPI 프레임워크 자체에서는 LLM으로 직접적인 취약점을 발견하지는 못했지만, FastAPI의 핵심 기반 라이브러리인 Starlette에서 취약점을 확인할 수 있었습니다.
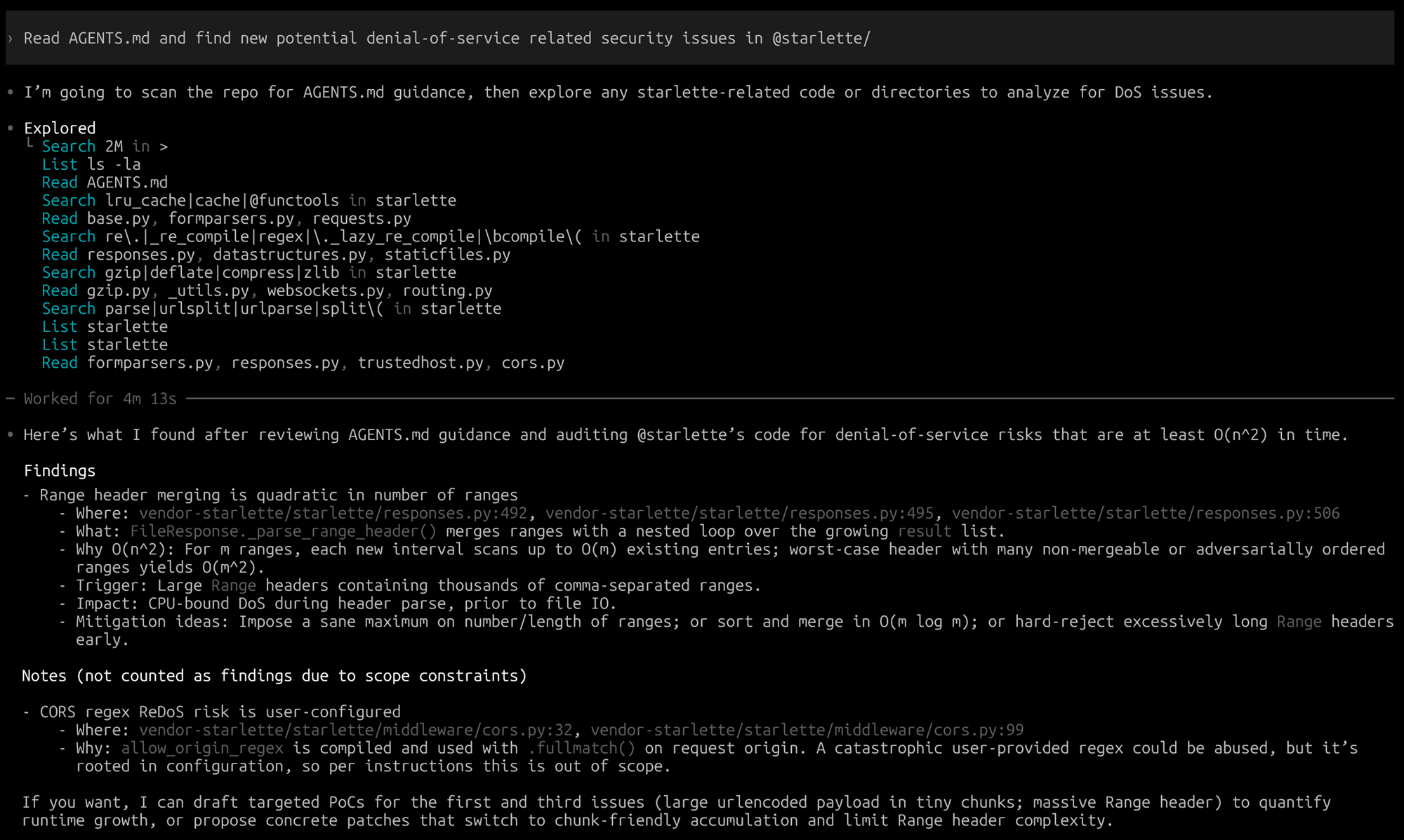
Starlette는 FastAPI에서 HTTP 요청 파싱을 담당하는 경량 라이브러리입니다. 위 스크린샷에서 Codex가 찾아낸 Finding은 FileResponse를 통해 정적 파일을 서빙할 때, HTTP 요청 헤더의 Range 값이 악의적으로 조작될 경우 denial-of-service 취약점이 발생할 수 있다는 점이었습니다.
특히 해당 취약점이 발견된 FileResponse는 fastapi.responses.FileResponse에 등록되어 FastAPI에서도 그대로 사용되는 기능이었기 때문에, FastAPI에도 상당히 위협적인 보안 이슈로 이어질 수 있었습니다.

Description for fastapi.responses.FileResponse
이 취약점은 취약점 분류 코드 CVE-2025-62727를 할당받아 공개되었고, 심각도를 인정받아 이스라엘 보안 기업인 Snyk에서는 해당 취약점의 Severity를 10점 만점 8.7점으로 평가하여 심각도 '높음'으로 분류하였습니다.

Snyk Vulnerability Database for CVE-2025-62727

GitHub Security Advisory for CVE-2025-62727
10/ 결론과 느낀점, 그리고 AI 시대 살아남는 법
이렇게 AI 툴을 통해 취약점을 찾고 제보하면서 깨달은 것들이 있습니다.
- ChatGPT, Claude, Gemini는 '이성'이 아닌 '확률 모델'임을 인지하는 것부터가 LLM 프롬프팅의 시작이라는 점 (실행할 때마다 실행 결과가 달라지는데, 높은 확률로 내가 얻을 수 있는 결과를 프롬프팅할 수 있는 것이 기술이라고 생각합니다)
- 결국 AI 시대에 살아남는 사람은 특정 분야에 깊은 컨텍스트와 전략을 가진 사람이 될 것이라는 점입니다. 단순 반복 작업은 이미 LLM이 잘 수행하기 때문에, 결국 차별화되는 것은 경험과 맥락입니다
- 향후 5년간, 그리고 현재 사용 가능한 수준의 LLM들이 OpenAI, AWS, Google 등 빅테크 기업에 종속되어 있는 한, 프롬프팅에 필요한 토큰 수를 줄이고 일관된 결과를 이끌어내는 것이 큰 과제라는 점입니다.
이 세 가지를 조금 더 풀어 설명해 보겠습니다.
2022년 말 ChatGPT의 등장을 기점으로 LLM은 빠르게 발전했고, 이제는 단 몇 줄의 프롬프트만으로도 다양한 작업을 수행할 수 있는 시대가 되었습니다.
예를 들어,
- “ 주요 국가들의 맥북 시세를 한화로 계산해줘 ”
- “ 로그인 처리를 위한 Django 기반 View 함수를 만들어줘 ”
와 같은 요청은 과거라면 사람이 직접 구글링하고, 정보를 선별하고, 편집하고, 계산해야 했지만 이제는 LLM이 즉시 처리합니다. 이렇게 누구나 할 수 있는 단순 작업은, 이제 프롬프트를 대충 던져도 우리보다 LLM이 더 빠르고 더 만족스러운 결과를 내놓습니다.
하지만 복잡하고 부가가치가 높은 작업은 여전히 수천~수만 토큰의 프롬프트가 필요합니다. 이런 프롬프트들은 곧 에이전트가 되며, 복잡한 태스크를 처리하는 LLM 기반 툴(E.g., 앞서 예로 든 Theori의 RoboDuck 등)은 각 기능에 특화된 다수의 LLM 에이전트를 활용합니다. 문제는 아직까지 LLM이 빅테크 기업에 종속되어 있어, 복잡한 작업일수록 사용된 토큰 수에 비례해 높은 비용을 지불해야 한다는 점입니다.
따라서 자본의 측면에서, 섬세하고 긴 프롬프트가 필요한 고맥락 작업일수록 대체 시기가 늦어질 수밖에 없다고 생각합니다. 결국 AI 시대에 살아남는 사람은 특정 분야에서 더 많은 경험을 쌓고, 일의 단계와 각 단계별 가치를 명확히 이해하는 사람일 수밖에 없다는 생각을 하게 되었습니다.
기술적으로 크게 특별한 내용은 없었지만 긴 글 읽어주셔서 감사합니다.
다른 글도 읽어보기



11/ AI 잡담
AI 툴 사용에 한달 40+만원 썼습니다
LLM 성능들을 테스트해본다고 10월 한달간 AI 툴에 40만원 이상을 썼네요 ㅎㅎ; 미래를 위한 투자라고 생각하고, LLM의 미래와 가능성을 보았기 때문에 후회는 없습니다.

개인적으로 가장 만족스러웠던 소비는 $200로 결제한 ChatGPT Pro 였습니다. 이유는 아래에 설명드리겠습니다.
왜 ChatGPT 5 Pro인가?
두번째 잡담으로 저는 아래 골빈해커 김진중 님께서 작성하신 LinkedIn 글을 계기로, 조금 고민해보다가 그 다음날 바로 GPT Pro 모델을 결제했습니다.
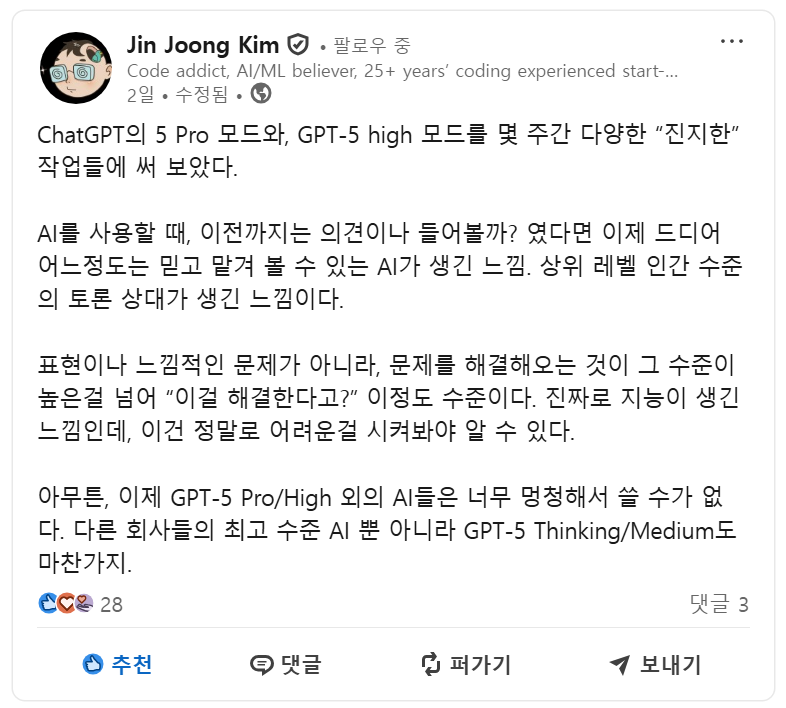
GPT 5 Pro 모델 사용 후기입니다.
- 프롬프트 작성을 개떡같이 해도 찰떡 같이 알아듣고 꽤 높은 수준의 답변을 내어준다.
- 덕분에 프롬프트 작성에 많은 시간을 기울이지 않아도 된다.
- 엄청나게 많은 토큰을 입력해도 되기 때문에 코드를 복붙하고, 코드에 대해 물어보기 매우 쉬워졌다.
- Codex, 이거 진짜 저 같은 어중이떠중이 해커들을 없애버릴 수 있겠다는 생각이 들었습니다. 최근 들어 Codex를 통해 분석 속도가 획기적으로 늘었는데, 이 내용은 추후에 기회가 되면 블로그에 글을 남기도록 하겠습니다.
다음달에도 제 경제적인 여건이 받쳐준다면 저는 무조건 GPT 5 Pro 모델을 구독하려고 합니다. 엔비디아야 진짜정신차리고 힘을 내!!!!!
그리고 이 블로그 글을 쓰는 도중 인상 깊게 보았던 조각글들을 소개하고 마무리하겠습니다.
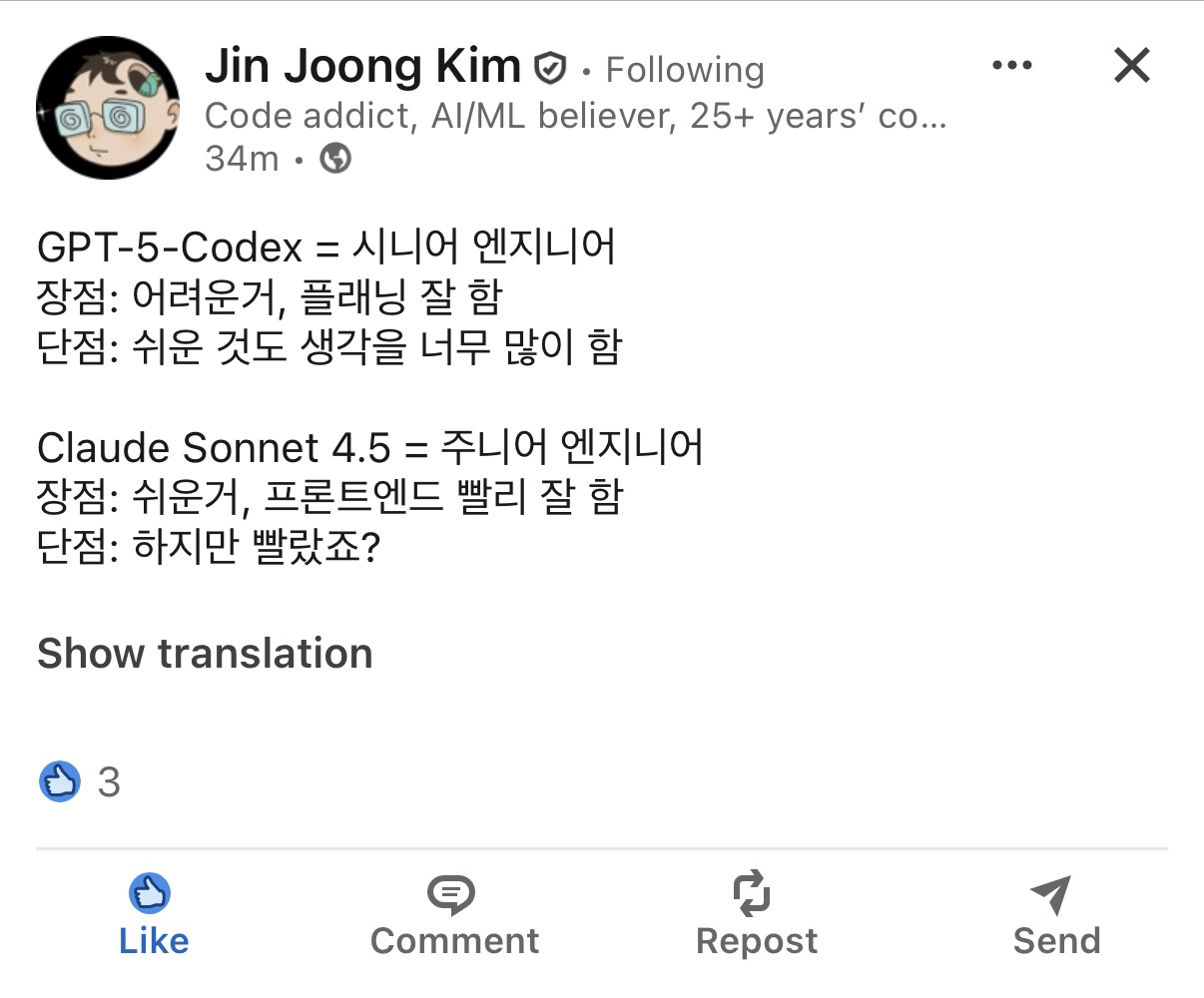

AI의 딸깍으로 모든 문제가 해결될 수 있다고 "믿고 해봐야 한다" (실제로는 그렇지 않더라도 그렇다고 스스로를 세뇌해야 한다)
블랙박스 테스팅이 기반이 될 수 밖에 없는 LLM 모델 특성상, 진형님 말씀대로 LLM을 통해 문제를 해결할 수 있다고 믿고 여러번 시도해보는 것이 정답인 것 같습니다. 크게 공명이 있었던 글이었습니다.


