How I Found a $2,418 Vulnerabilities with a $5 Prompt
How I used an LLM to find 6 security issues in Django, earning 2 CVEs (CVE-2025-64458, CVE-2025-64460), plus CVE-2025-62727 in FastAPI/Starlette.

Hi I'm Seokchan Yoon. Currently working for blockchain security audit company Zellic.io and also a member of the security team of Apache Foundation's Airflow project
Two months ago, I've twitted by saying that I'd found two reportable bugs for just $5.
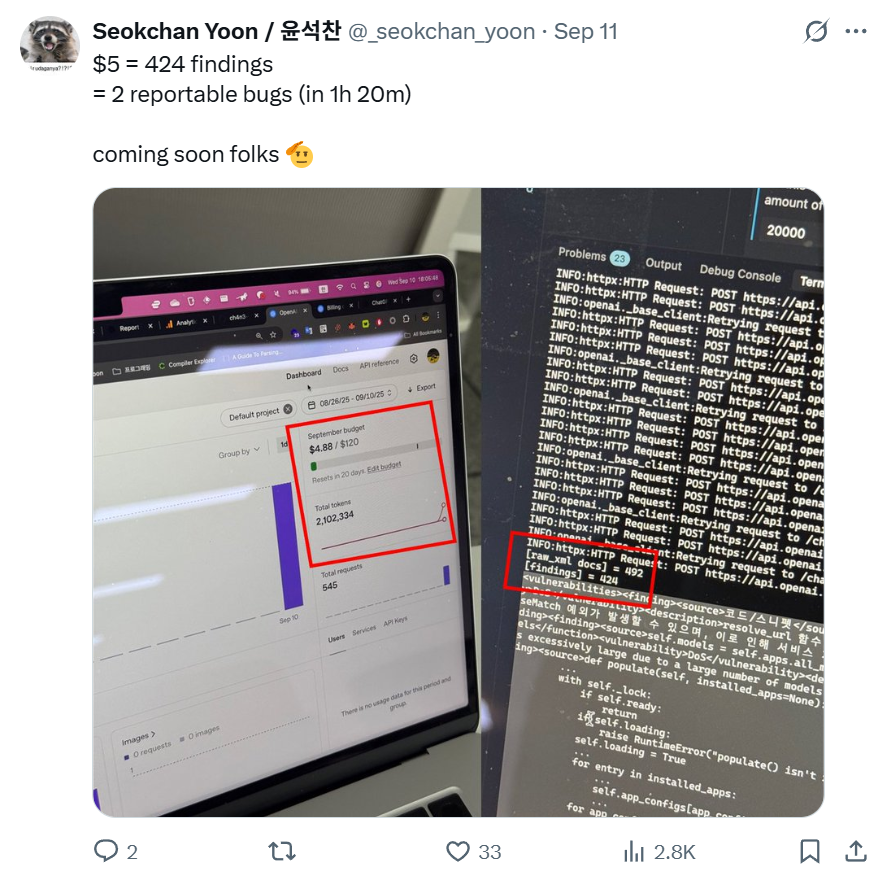
To cut to the chase: using an LLM, I found 6 issues in Django and reported them to the Django Security Team. Of those, two were judged a valid security issue and assigned a CVE (CVE-2025-64458, CVE-2025-64460). Using the same prompt, I also found a vulnerability in FastAPI (specifically Starlette), where an unauthenticated user could exploit server implements to trigger a denial-of-service (CVE-2025-62727).
Because this was the first vulnerability I've found purely with an LLM, I wanted to share my experience.
I did the LLM work in late September to early October; triage, patch, and disclosure wrapped up in November, so publication ended up later than I'd hoped.
1/ Why I Started Using LLMs to Find Vulnerabilities
(1) DEF CON 33 CTF Finals — Live CTF
I competed at DEF CON 33 CTF this August. (You can also read my review for the this DEF CON in the link below)


Every year, the finals include Live CTF, a tournament‑style event where one player from each team races head‑to‑head. And because the player's screen is broadcast on YouTube, so that you can literally watch world‑class hackers in action — what tools they use, how they solve challenges, and so on.
Since ChatGPT kicked off the LLM wave, most teams have shown up with their own LLM systems. Our first opponent team, the BlueWater, fed IDA's decompiled pseudo‑code straight into their model and pulled flags out. Watching that, I thought:
- Hackers can now use LLMs to radically speed up their analysis, PoC and exploit writing.
- And the gap between the hackers who leverage LLMs and those who don't is only going to widen.
(2) AI Cyber Challenge (AIxCC)
DARPA's AI Cyber Challenge also ran at DEF CON. Teams used AI models to automatically analyze binaries, identify and analyze vulnerabilities, patch them—end‑to‑end, no human interruption in the whole execution. What I really surprised in this special-format competition was, the winning team, Team Atlanta, discovered an unintended SQLite3 0‑day during qualifiers.
We discovered three 0day bugs pic.twitter.com/RmhJxWPpsR
— Team Atlanta (@TeamAtlanta24) August 10, 2025
I've heard some said—automatic vulnerability finding with AI—for years, but seeing a fully automated, LLM‑driven tool hit a new vulnerability in a major component felt… kinda unbelievable.
So after the Live CTF and AIxCC, I began to plan to build an LLM‑based tool that could help in my actual task for finding new security issues.
2/ After DEF CON & AIxCC
So after AIxCC ended, teams published their code archives on GitHub. I dug into Team Atlanta and Theori's repos.
Team Atlanta's repo:
Theori's repo:
Theori, in particular, posted a detailed their write‑up of the approach and implementation for their CRS, RoboDuck. I read it several times—it resonated and gave me the push I needed.

Analyzing the AIxCC archives, I started to believe I can use an LLM to find real vulnerabilities myself.
3/ Setting the Goal
Since 2023 I've reported 8 vulnerabilities across Python, Django, and django‑rest‑framework.
I know Django's codebase best, and through sending both valid and invalid reports I've accumulated a good sense for what the Django team accepts as a real security issue. So I set my target: use an LLM to find vulnerabilities in Django itself.
4/ System Design
Theori's RoboDuck warns that it can cost around $1,000/hour to run. That sounds it's too high cost for 'finding bugs with an LLM,' but there are some reasons:
- It had to analyze binaries, not scripts.
- Even scheduling the steps used the LLM.
- It generated PoCs to validate findings.
- It even patched the binaries.
Django, by contrast, is a relatively smaller script based codebase. So I believed I could get results for far less. Also unlike AIxCC's 'everything must be automated' rule, I don't need to make everything automated. So I planned to automate only the candidate mining step—e.g., gather lots of plausible, often false‑positive‑ish findings—and then I manually verify.
So my minimalized pipeline was:
- Provide a system prompt saying 'find potential vulnerabilities' and feed Django source code as the user prompt.
- Aggregate code segments the LLM flags as suspicious (including false positives).
- Analyze all the LLM's findings together.
Spoiler: I didn't even do step (3) myself—GPT‑5 Pro did the triage for me.
5/ Prompting
My prompt was based on the one RoboDuck used, so the early version wasn't much different from RoboDuck's
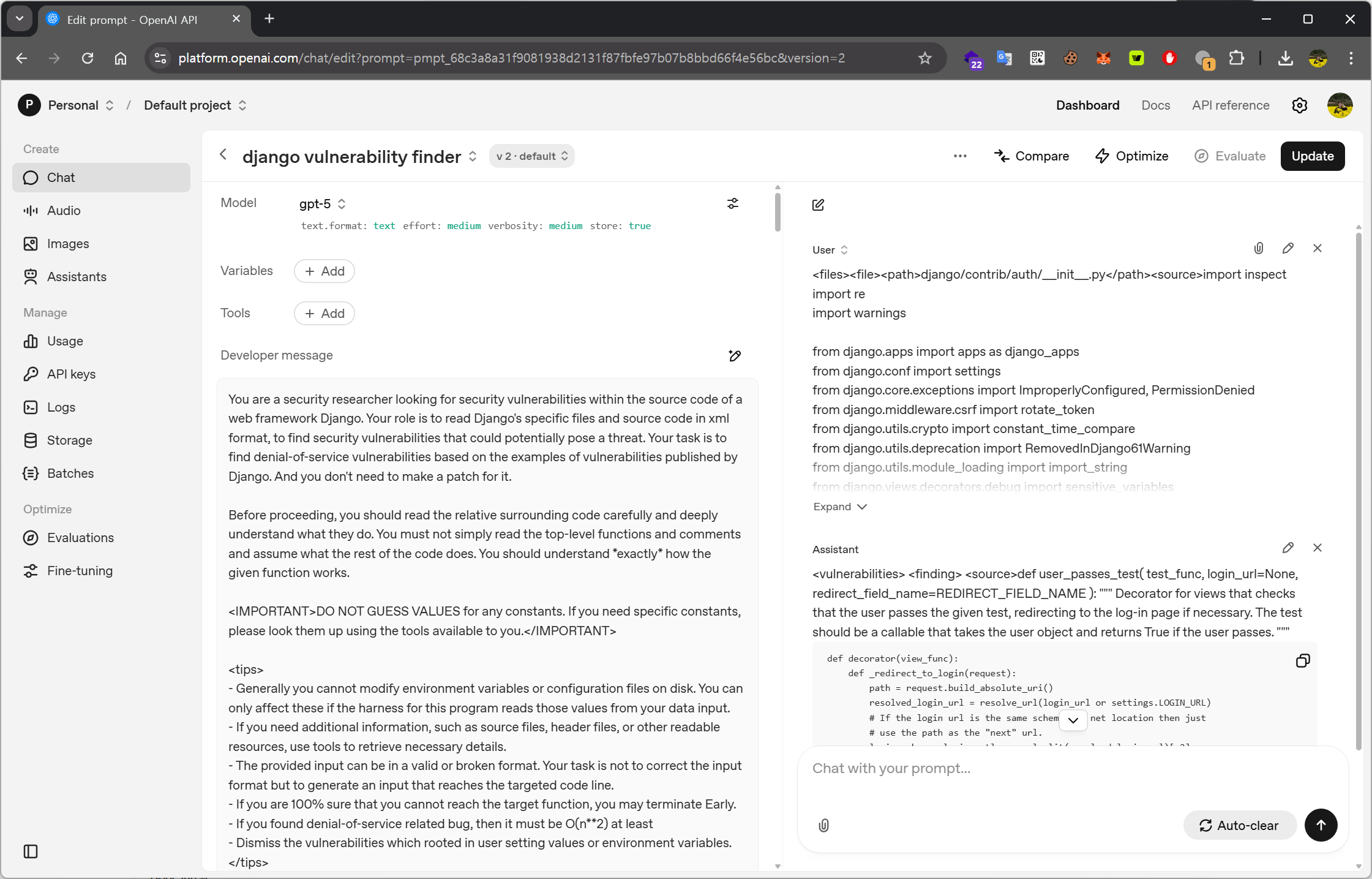
By using OpenAI's Playground feature, you can run both system prompts and user prompts and immediately check the results.
For reference, the reason I tested prompts in this Playground from the beginning, instead of using ChatGPT or Codex directly, was because I wanted to explore expanding them into a more general-purpose environment through OpenAI's API.
Then, let me explain a bit about the prompt I wrote.
Gadgets I Used for Prompting
(1) At the beginning, I specified to the LLM that it was a “Security Researcher looking for security vulnerabilities in Django.” As many of you probably know by now—since it's been quite a while since the OpenAI team released their Cookbook—assigning a role allows you to give the model a specific "persona," letting it know in just a few tokens what perspective or attitude it should adopt when responding.
You are a security researcher looking for security vulnerabilities within the source code of a web framework Django. Your role is to read Django's specific files and source code in xml format, to find security vulnerabilities that could potentially pose a threat. Your task is to find denial-of-service vulnerabilities based on the examples of vulnerabilities published by Django.
(2) Because LLMs tended to waste tokens suggesting patches whenever they spotted a vulnerability, I made sure to clarify that generating patches wasn't necessary.
And you don't need to make a patch for it.
(3) I can't recall exactly where I came across the phrase “After reading and deeply understanding the code …”, but including it seemed to boost the quality of the answers a bit. In this case, I simply reused the sentence Theori had used in RoboDuck.
Before proceeding, you should read the relative surrounding code carefully and deeply understand what they do. You must not simply read the top-level functions and comments and assume what the rest of the code does. You should understand *exactly* how the given function works.
Similarly, in Google DeepMind's tips, they also reported that adding the phrase “Take a deep breath and work on this problem step by step” led to better performance, so I didn't think this idea was entirely without basis.

(4) I also included a sentence using the <IMPORTANT> tag to tell the model not to guess values that had already been specified as constants. (This was taken directly from Theori's RoboDuck prompt. Out of curiosity, I tested the difference with and without this phrase, and the accuracy was noticeably higher when it was included.)
<IMPORTANT>
DO NOT GUESS VALUES for any constants. If you need specific constants, please look them up using the tools available to you.
</IMPORTANT>
(5) I used the <tips> tag to lay out more specific conditions. While most of this came from Theori's RoboDuck prompt, I supplemented it with additional guidance—drawing on Django's security policies—so the LLM could more effectively assess whether a vulnerability was valid.
<tips>
- Generally you cannot modify environment variables or configuration files on disk. You can only affect these if the harness for this program reads those values from your data input.
- If you need additional information, such as source files, header files, or other readable resources, use tools to retrieve necessary details.
- The provided input can be in a valid or broken format. Your task is not to correct the input format but to generate an input that reaches the targeted code line.
- If you are 100% sure that you cannot reach the target function, you may terminate Early.
- If you found denial-of-service related bug, then it should be O(n**2) at least
- Dismiss the vulnerabilities which rooted in user setting values or environment variables.
...
</tips>(6) I included three sample vulnerabilities together with the patch commit diffs. Showing how known security issues had been fixed helped highlight the code patterns that gave rise to those vulnerabilities. I decided to feed code diffs into the prompt after reading Theori's blog, which mentioned that agents tend to produce fewer false positives when they can reference diffs
When given a diff, this task is much simpler: an LLM agent is given the diff itself and asked to look for bugs caused by the change. We use two agents in parallel, one with a version of the diff that is pruned to remove code that may not be relevant, based on compilation introspection. This analysis has far fewer false positives given its drastically reduced scope.
https://theori.io/blog/aixcc-and-roboduck-63447
I prompted the LLM to identify denial‑of‑service vulnerabilities. To guide it, I included some representative Django code patterns known to cause DoS issues, together with descriptions and diffs from 1‑day CVE records.
The specific vulnerabilities I provided diffs for were:
- CVE-2023-23969: Potential denial-of-service via
Accept-Languageheaders - CVE-2025-27556: Potential denial-of-service vulnerability in
LoginView,LogoutView, andset_language()on Windows - CVE-2024-56374: Potential denial-of-service vulnerability in IPv6 validation
(7) Showing output and formatting examples: this is such a common technique that it hardly needs further explanation.
After that, I passed the source code to the completed agent as a User Prompt. At this point, I developed it so that the source code would be wrapped in XML format when sent, and the reason I chose this format was because I referred to suggestions previously made by OpenAI developers.
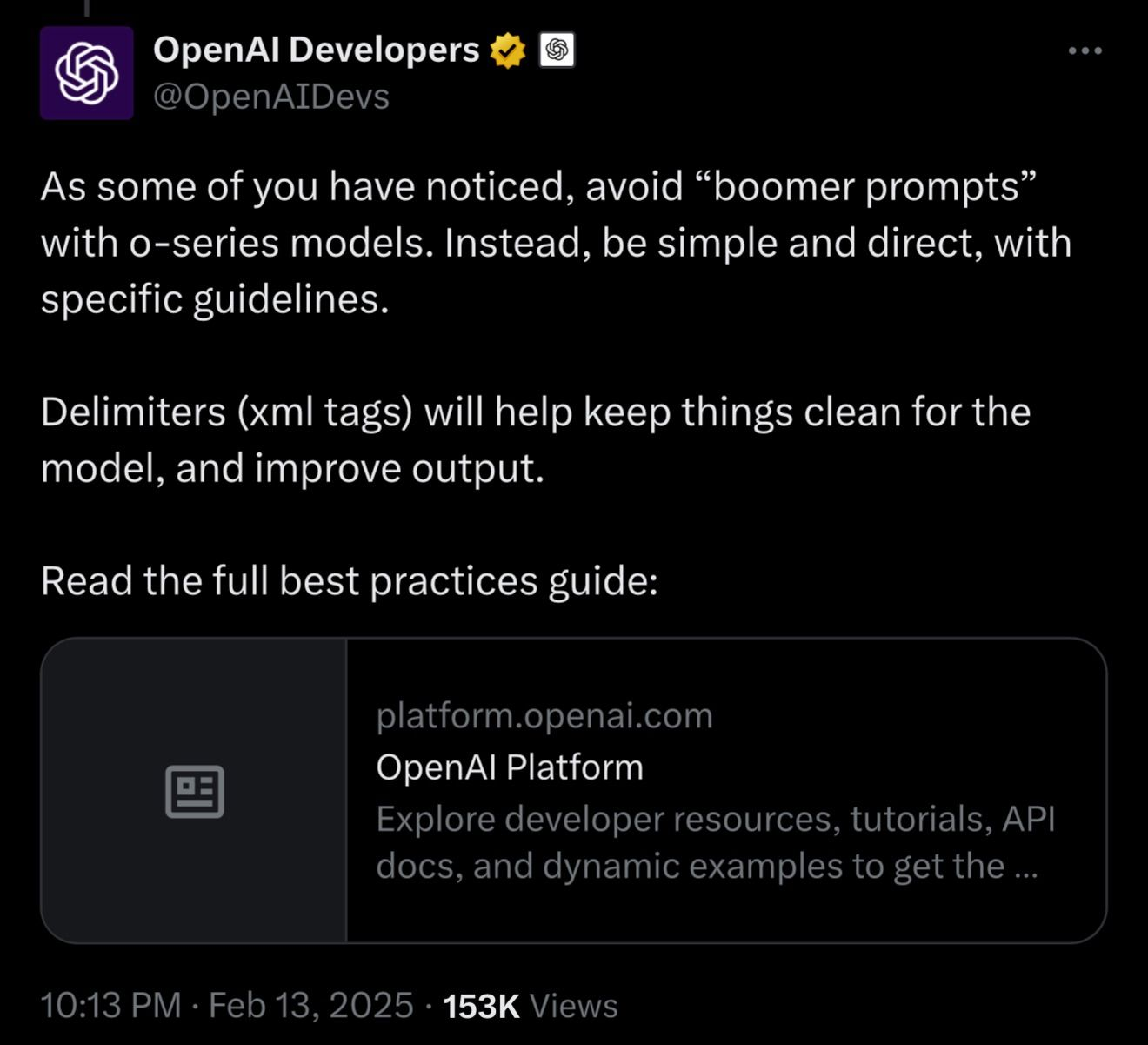
Since most prompting with LLMs is still being researched primarily through black‑box testing, I don't think there's a single right answer. However, I do believe there are types of prompts that can, with fewer tokens, specify a concrete task, probabilistically improve response quality, or encourage the model to use fewer response tokens. Unlike a regular Python script, each run costs me OpenAI credits I’ve purchased with my own money, so I put as much care as I could—within what I know—into crafting the prompt.
6/ Source Code XML Bundling
When using LLM services like ChatGPT, many of you may have experienced that as the token count of a request grows too long, the response accuracy tends to decline. Keeping this in mind, I instructed the model to read source code only within a range that wouldn’t make the token count excessively large. With that in mind, I limited the source code input so the token count wouldn’t grow too large—keeping each XML‑wrapped file bundle under 40K tokens. Even with long API calls, execution finished within 1–2 minutes, and the response quality was still fairly solid (though that’s my subjective impression).
To feed GPT‑5 the source code, I wrapped it in XML like this and asked it to look for vulnerabilities:
<files>
<file>
<path>django/utils/__init__.py</path>
<content>[...]</content>
</file>
<file>
<path>django/utils/archive.py</path>
<contnet>[...]</contnet>
</file>
[...]
</files>I tried to bundle together files from the same directory so that functionally related files could be analyzed at once. If bundling all files in a directory exceeded 40K tokens, I implemented a recursive process that bundled each subdirectory separately into XML.
For the system prompt, I included RoboDuck‑based instructions from Theori, and for the user prompt, I provided both an example of the expected output and the XML‑bundled source code, which were then passed to the GPT‑5 model via the OpenAI API.
Applying this initial version of the LLM‑based vulnerability analyzer to the entire Django source code and sending the prompts to GPT‑5 through the OpenAI API resulted in a total execution cost of around $5.
7/ Collecting False Positives
When I gathered the suspicious code segments, I was surprised at how many blind spots I had missed. Having read through Django's source code for years, I thought there were no more vulnerabilities to be found in certain parts—but I was genuinely surprised to see the GPT‑5 model uncovering plausible security issues there.
These days, don't you also use LLMs when solving CTF challenges? In my case, whenever I was solving CTF challenges, I often thought to myself, “Well, I'll be fine for a few more years,” after seeing how many LLM models couldn't even properly identify valid vulnerabilities. But after reviewing the findings GPT‑5 produced, I began to think that even the domain of vulnerability analysis—which I once believed AI could never touch—might soon be fully handled by LLMs, provided they're given enough context and an appropriate tokens.
Here's some examples of a finding that the Django Team didn't officially accept, but that still made me stop and think, “Wait, an LLM actually found this?”
(1) Finding # 1
Potential DoS vulnerability in File.__iter__() due to quadratic-time concatenation
In Django, all file-related classes inherit from the base class File
<finding>
<source>def __iter__(self):
# Iterate over this file-like object by newlines
buffer_ = None
for chunk in self.chunks():
for line in chunk.splitlines(True):
if buffer_:
if endswith_cr(buffer_) and not equals_lf(line):
# Line split after a \r newline; yield buffer_.
yield buffer_
# Continue with line.
else:
# Line either split without a newline (line
# continues after buffer_) or with \r\n
# newline (line == b'\n').
line = buffer_ + line
# buffer_ handled, clear it.
buffer_ = None
# If this is the end of a \n or \r\n line, yield.
if endswith_lf(line):
yield line
else:
buffer_ = line
if buffer_ is not None:
yield buffer_</source>
<path>django/core/files/base.py</path>
<function>File.__iter__()</function>
<vulnerability>potential denial of service via quadratic-time line iteration</vulnerability>
<description>When iterating a file with very long lines (e.g., no newline characters), the loop repeatedly concatenates the growing buffer with the next chunk (line = buffer_ + line). This yields O(n^2) time due to repeated copying of ever-larger strings/bytes across chunk boundaries. An attacker can supply a large newline-free file and trigger CPU exhaustion in any code that iterates over File objects line-by-line.</description>
</finding>According to the above finding from GPT‑5, when iterating over the contents of a File, the next chunk is processed with the code line = buffer_ + line, which causes excessive copying of byte strings and can lead to a denial‑of‑service. Therefore, with code of the type shown below, a Django server could indeed fall into a denial‑of‑service state.
import time
from django.core.files.base import ContentFile
def test(length):
print(f"[DEBUG] Length : {length}")
data = b'a' * length
start_time = time.time()
f = ContentFile(data)
for _ in f:
pass # only yields once, but concatenation occurs internally
end_time = time.time()
print(f"[DEBUG] Time Elapsed : {end_time - start_time:.4f} seconds")
if __name__ == "__main__":
for i in range(1, 10):
test(10 ** i)And the result of code above shows
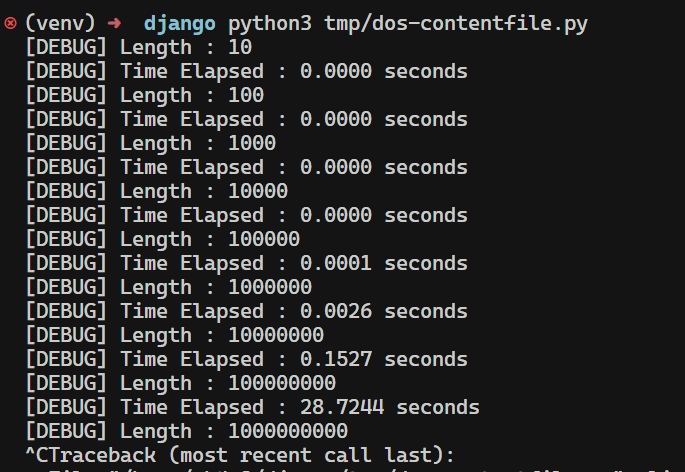
The Django Security Team noted that this issue only begins to trigger with files larger than 100KB, and therefore did not consider it a practical security issue.
However, I personally hadn’t realized that this kind of Python code pattern (line = buffer_ + line) could lead to a potential denial‑of‑service due to memory allocation problems until I wrote the PoC myself. What really struck me was that the LLM surfaced a potential issue not through a typical CTF‑style trick, but by highlighting a new kind of code pattern I hadn’t considered before.
(2) Finding # 2
Potential DoS Vulnerability in AbstractBaseUser.normalize_username()
Did you know that in Windows environments, performing NFKC normalization on large Unicode strings can potentially cause a denial‑of‑service? Django actually has quite a few patches in place for this reason.
<vulnerabilities>
<finding>
<source>class AbstractBaseUser(models.Model): ... def clean(self): setattr(self, self.USERNAME_FIELD, self.normalize_username(self.get_username())) ... @classmethod def normalize_username(cls, username): return ( unicodedata.normalize("NFKC", username) if isinstance(username, str) else username )</source>
<path>./base_user.py</path>
<function>AbstractBaseUser.clean()/normalize_username()</function>
<vulnerability>Potential denial-of-service via unbounded NFKC normalization of username</vulnerability>
<description>AbstractBaseUser.clean() unconditionally normalizes the username by calling normalize_username(), which applies unicodedata.normalize("NFKC", ...) to attacker-controlled input without any length limit. Django ModelForms invoke model.clean() even when a field (e.g., username) already has validation errors such as exceeding max_length, so this normalization still runs on oversized inputs. On Windows, NFKC normalization can be pathologically slow (quadratic or worse) for certain crafted Unicode strings. An attacker can submit an extremely large username to user creation/update views (e.g., UserCreationForm/AdminUserCreationForm), causing excessive CPU usage and a denial of service. While UsernameField.to_python() guards normalization by max_length, this model-level path lacks any upper bound and can be triggered despite prior form validation failures.</description>
</finding>
</vulnerabilities>This finding from GPT‑5 also pointed out an issue that can arise during the NFKC normalization of Unicode strings. It resembles the code pattern from the 1‑day vulnerability I exampled in system prompt, CVE‑2025‑27556. What made it especially striking for me was that, despite analyzing Django’s source code for years, this was an area I had completely overlooked.
To put it simply, the AbstractBaseUser class—which serves as the foundation for all user‑related classes in Django—internally calls normalize_username() when creating a user with create_user() or converting a value with to_python(). However, since this function does not perform length validation on the input username, if a programmer passes user input directly into create_user() without additional checks (such as length limits or Unicode validation), the system can enter a denial‑of‑service state when processing very large Unicode strings.
The PoC below shows how simply passing unchecked input into create_user() could expose this weakness:
def test(bytes_length):
from django.contrib.auth.models import User
initial = "⅓"
payload = initial * (bytes_length // len(initial.encode()))
start_time = time.time()
try:
username = f"{payload}_{int(time.time() * 1000000)}"
print(f"[DEBUG] username length: {len(username.encode())}")
print(f"[DEBUG] username character count: {len(username)}")
User.objects.create_user(username=username) # <- here
end_time = time.time()
print(f"[DEBUG] Time elapsed: {end_time - start_time:.4f} seconds")
print(f"[SUCCESS] User created successfully")
except Exception as e:
end_time = time.time()
print(f"[DEBUG] Time elapsed: {end_time - start_time:.4f} seconds")
print(f"[ERROR] Exception occurred: {e}")
print("-" * 50)Django's Security Policy makes it clear that developers are responsible for validating user input before calling framework methods. Problems caused by skipping that step aren't treated as official security issues, but as ordinary bugs. Unsurprisingly, this particular finding wasn't accepted as a security vulnerability.
Even so, I found it persuasive. Despite years of digging through Django's source, I had missed this small bug. What struck me most was realizing that an LLM could act as a safety net—catching the kinds of oversights even experienced developers or security researchers might miss. (kinda fool-proof and fail-proof)
8/ Root Cause and Validity Analysis with ChatGPT
When I first built this LLM‑based vulnerability analyzer, my idea was simple: let GPT‑5 detect vulnerabilities and output them in XML, and then I'd personally decide whether they were valid. I've reported dozens of vulnerabilities over the years, and I believed I had a better sense than an AI of which bug patterns the Django Security Team would actually treat as security issues.
At the same time, however, I wondered whether the AI might possess stronger analytical ability and faster speed than I did. So before reviewing the vulnerabilities myself, I asked the GPT‑5 Pro model to verify their validity and even generate PoCs—and the results were quite surprising.
One example that stood out was a potential denial‑of‑service issue in Django’s template engine numberformat filter. The idea was that if you passed in an extremely large numeric string, it could trigger a DoS. When I tried to reproduce the PoC myself, it didn’t seem to work, and I was ready to dismiss it as a false alarm. But just as I was about to write it off...
(Since I had prompted in Korean, I apologize for providing a hard‑to‑read screenshot 😓 The detailed description is under the screenshots below)
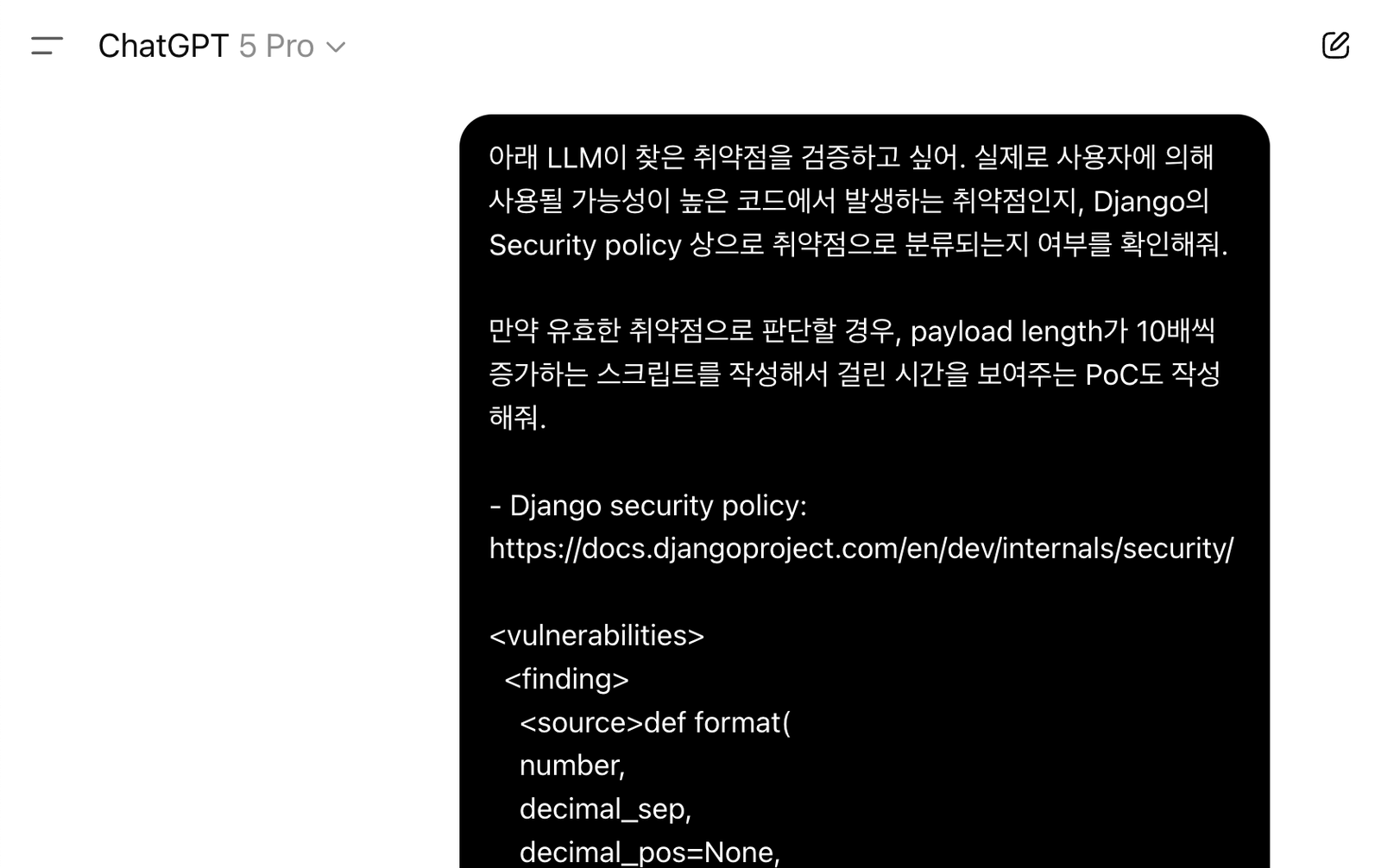
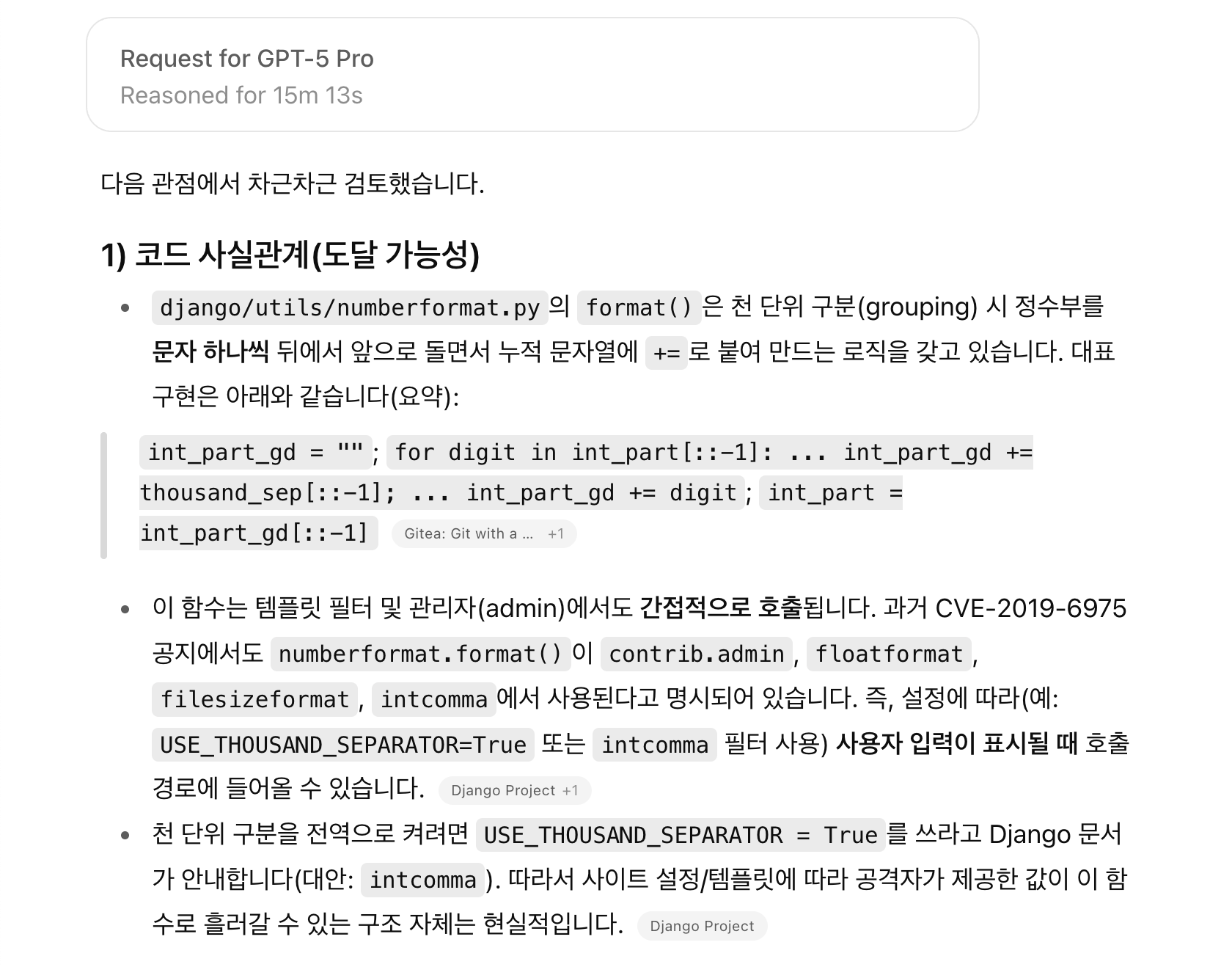

About 15 minutes later, ChatGPT responded: "This has already been mitigated in CPython, but it may still be vulnerable in a PyPy environment." At the time, I had only assumed a CPython environment when trying to reproduce the PoC, which is why I couldn't trigger the bug. After following ChatGPT's suggestion, I set up a PyPy environment and ran the PoC again, and this time the vulnerability reproduced perfectly. Although I knew that CPython and PyPy had different implementations, I had never considered that this difference could directly affect whether a potential security issue could be triggered—so it was quite a shock to me.
Although the Django team did not accept this bug as a valid vulnerability, since it was dependent on PyPy, I came away from the experience with three important realizations:
- This specific code pattern can indeed lead to a practical denial-of-service issue.
- In Python, whether a vulnerability can be triggered may depend on the runtime environment (CPython, PyPy, ...)
- Even though I couldn't reproduce or analyze the root cause myself, ChatGPT Pro was able to clearly explain it based on the code context.
Through this process, I became convinced that ChatGPT might actually possess stronger analytical capabilities than I do.
9/ Finding Vulnerabilities More Easily with Codex
After purchasing the ChatGPT Pro plan, I switched my script from using the OpenAI API to using Codex. This way, I could apply a method where the Codex CLI tool actively read through the Django source code to find vulnerabilities, without incurring additional costs.
I wrote the same prompt I had previously used with the OpenAI API into an AGENTS.md file, and then instructed Codex to look for new denial‑of‑service vulnerabilities based on the Instructions written in that file.
After making the above request, the vulnerabilities that Codex actually found and summarized are as follows.
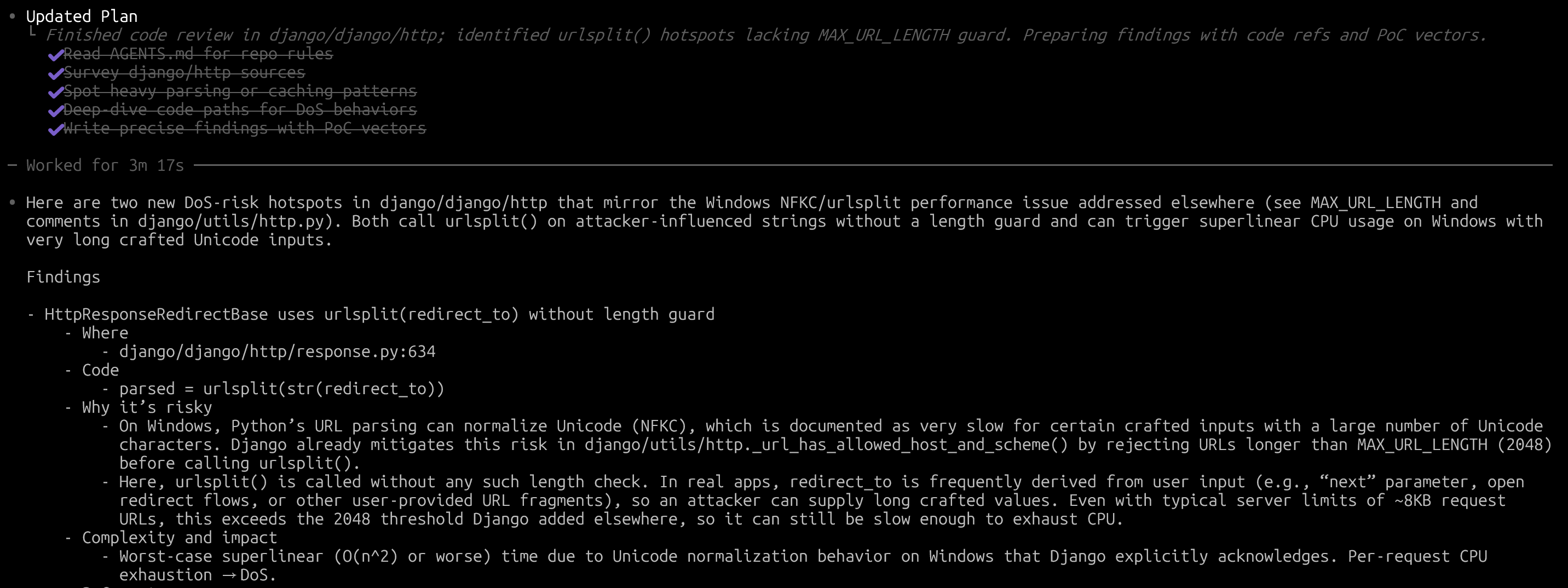
In short, Codex uncovered a potential issue in Django's HttpResponseRedirectBase class. When generating responses, the framework wasn’t validating URL length, which meant that processing the hostname could open the door to a denial‑of‑service attack.
Based on this finding from Codex, I created a PoC, verified the vulnerability myself, and then reported it to the Django Security Team.
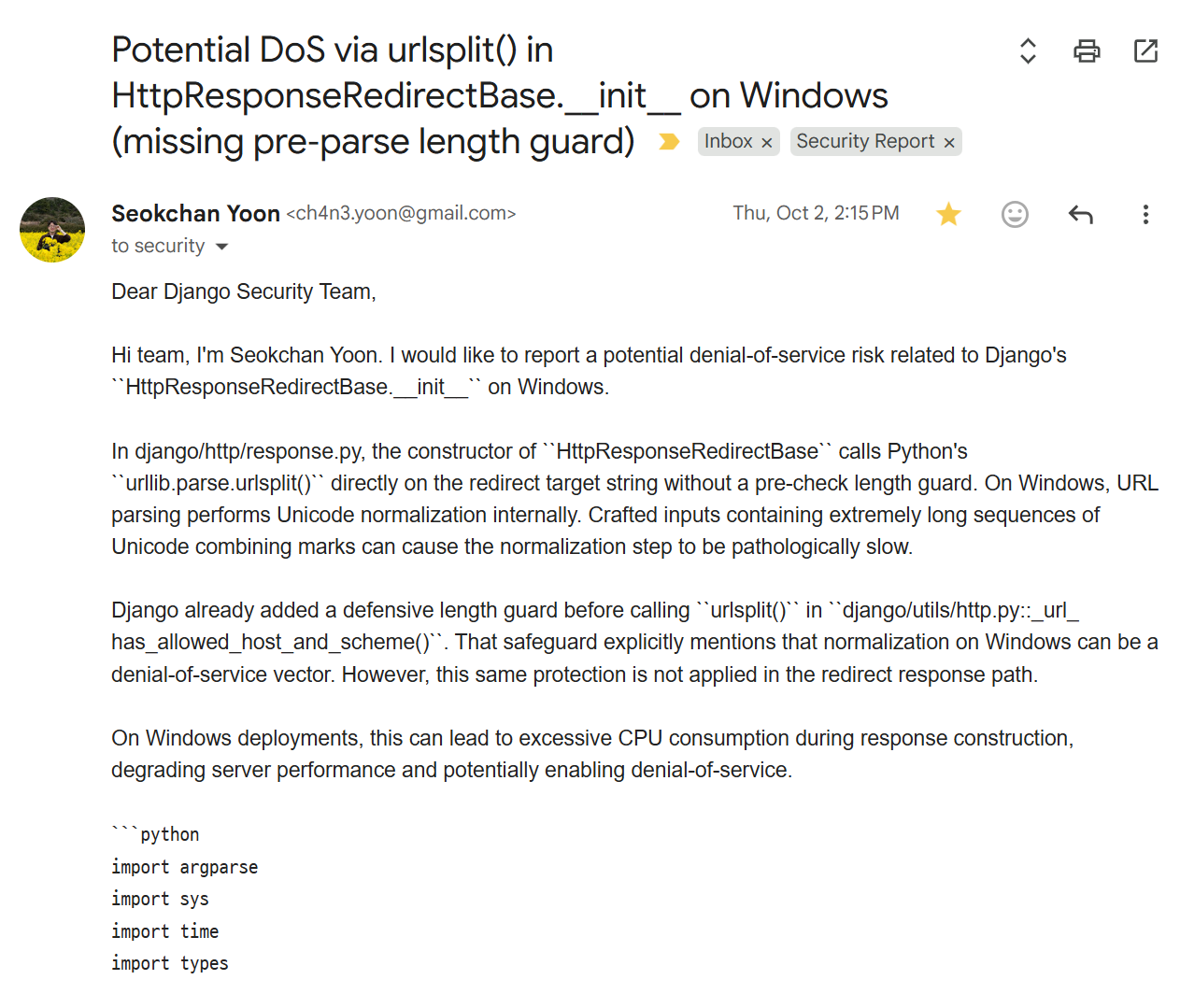
And the result was...
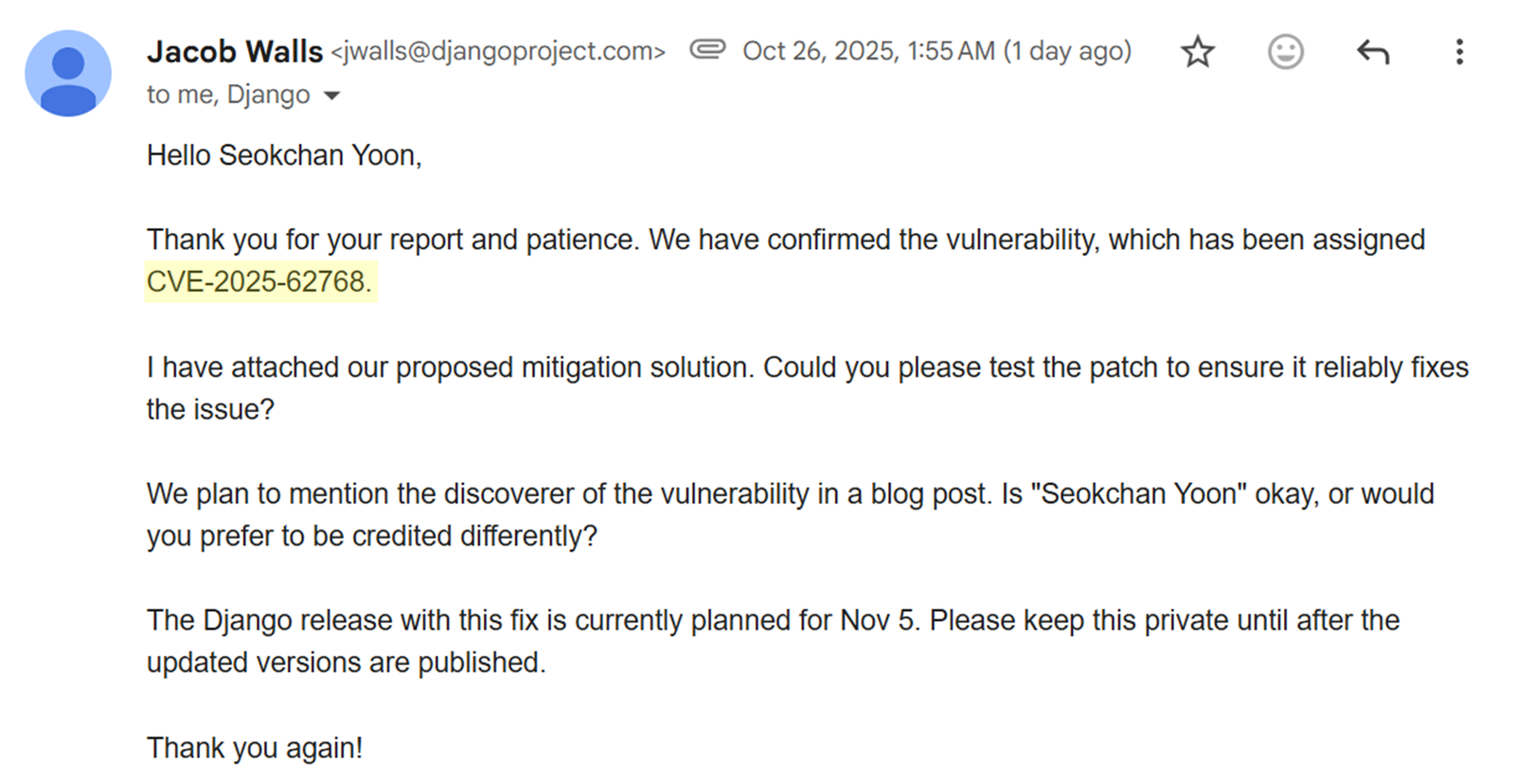
The vulnerability was successfully recognized as valid. As a result, it was officially registered as CVE‑2025‑62768, and the Django team evaluated it as a medium‑severity denial‑of‑service issue. (However, for some reason, it was changed to CVE-2025-64458) Accordingly, it was acknowledged on HackerOne as a vulnerability eligible for a reward of $2,163.
9‑1/ (Bonus) Finding Vulnerabilities in FastAPI
I applied the same AGENTS.md prompt that I had used when asking for vulnerabilities in Django to FastAPI as well. While the LLM did not directly discover vulnerabilities in the FastAPI framework itself, it did identify a vulnerability in Starlette, the core underlying library of FastAPI.
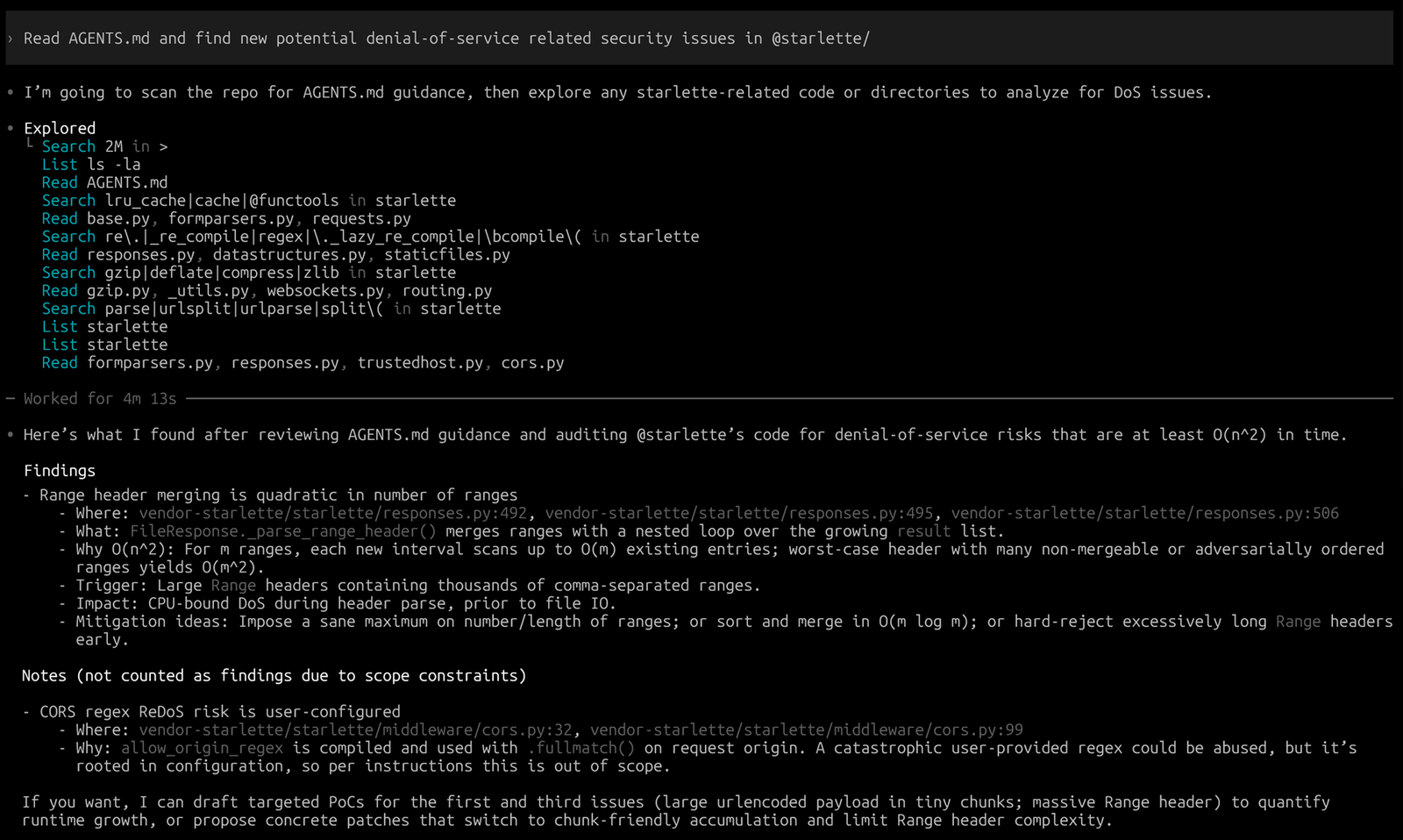
Starlette is a lightweight library responsible for HTTP request parsing in FastAPI. The finding Codex identified in the screenshot was that when serving static files through FileResponse, if the Range value in the HTTP request header is maliciously manipulated, a denial‑of‑service vulnerability could occur.
In particular, since the vulnerable FileResponse is registered as fastapi.responses.FileResponse and used directly in FastAPI, this could also pose a significant security issue for FastAPI itself.

Official Document for fastapi.responses.FileResponse
This vulnerability was assigned the identifier CVE‑2025‑62727 and publicly disclosed. Recognizing its severity, the Israeli security company Snyk rated it 8.7 out of 10 and classified it as High severity

Snyk Vulnerability Database for CVE-2025-62727

GitHub Security Advisory for CVE-2025-62727
10/ Conclusions, What I Learned, and Surviving the AI Era
Through the process of finding and reporting vulnerabilities with AI tools, I came to realize a few things.
- Recognizing that ChatGPT, Claude, and Gemini are not “reasoning engines” but probabilistic models is the starting point of LLM prompting. (Each run can yield different results, and the skill lies in prompting in a way that maximizes the probability of getting the outcome you want.)
- In the age of AI, the people who thrive will be those with deep context and strategy in a particular field. Repetitive tasks are already handled better by LLMs, so what sets humans apart is experience and contextual insight.
- As long as today's LLMs remain tied to big tech platforms like OpenAI, AWS, and Google, the challenge will be reducing token usage while still producing consistent results—especially for complex tasks.
Let me expand on these three points.
Since the release of ChatGPT at the end of 2022, LLMs have advanced rapidly, and we now live in an era where just a few lines of prompts can accomplish a wide range of tasks.
For example:
- "Convert the prices of MacBooks in major countries into US dollar"
- "Write a Django‑based View function for login handling."
Before few years ago, a person would have had to Google, filter, edit, and calculate this information manually. Now, LLMs can handle it instantly. For such simple tasks that anyone can do, even a rough prompt will produce results faster and more satisfactorily than we could ourselves.
However, complex and high‑value tasks still require prompts that span thousands or even tens of thousands of tokens. These prompts effectively become agents, and LLM‑based tools for handling complex tasks (such as Theori's RoboDuck mentioned earlier) rely on multiple specialized LLM agents. The problem is that LLMs are still dependent on big tech companies, so the more complex the task, the higher the cost—proportional to the number of tokens used.
But high‑value, complex work still demands prompts that run into thousands of tokens. These prompts effectively become “agents,” and sophisticated tools like Theori’s RoboDuck orchestrate multiple specialized LLM agents to tackle them. The catch is cost: the more tokens you use, the more you pay.
That's why I believe high‑context, domain‑specific work will be the last to be automated. To stay relevant, we need to deepen our expertise, understand the steps of our work, and know the value each step brings.
Thanks for reading my article so far.
You can find me more at the link below if you interested

https://ch4n3.kr/
Explore more articles



11/ Trivials
Spent over $300+ in a month
In October alone, I spent more than $300+ testing the performance of various LLMs. I think of it as an investment for the future, and since I've seen the potential and possibilities of LLMs, I have no regrets.

Personally, the purchase I was most satisfied with was ChatGPT Pro, which I subscribed to for $200. I'll explain the reasons below.
Review of Using the GPT‑5 Pro Model
- Even when I write prompts poorly, it still understands them perfectly and produces fairly high‑level answers.
- Thanks to that, I don’t have to spend much time crafting prompts.
Since it can handle an enormous number of tokens, it’s very easy to paste in code and ask questions about it. - Codex made me think it could really wipe out “half‑baked” hackers like me. Recently, my analysis speed has increased dramatically thanks to Codex, and I plan to write a blog post about this in the future when I get the chance.
As long as my budget can handle it, I'm absolutely planning to renew my GPT‑5 Pro subscription next month.
Memorable snippets I came across while drafting this post

"You must 'believe and try' that every problem can be solved with just a slight touch of AI (even if it's not actually the case, you must brainwash yourself into believing it)."
Given the nature of LLM models, which must be based on black-box testing, I completely agree with Jin-Hyung: the right answer is to believe that the LLM can solve the problem and simply try it repeatedly. This post resonated strongly with me.


