CVE-2023-23969: Potential denial-of-service via Accept-Language headers
Django의 Accept-Language 헤더 처리에서 발견된 DoS 취약점 CVE-2023-23969를 분석합니다. re.split()과 lru_cache의 조합이 원인입니다.

Overview
Hi guys, this is Seokchan Yoon.
The Django security vulnerability has released on February 1, 2023. Because I have big interest in Django, so I analyze this issue just in time. To see the detail for this issue, click the link below.
This security issue can lead your Django server down very easily. If the hacker sends several http requests which include attack payloads to your Django server, it will be down by DoS. Simply, it is caused by regex implemented by re.split(), and cache implemented by built-in function functools.lru_cache(). Let's see the detail.
How to get language from client's request?
Using get_language_from_request() function is one of the useful and easy method to get language from clients' http request. This function is defined in the file django/utils/translation/trans_real.py and you can check how to use this to see the example code and screen shot below.
from django.shortcuts import render
from django.utils.translation.trans_real import get_language_from_request
from django.http.response import HttpResponse
def example_function(request):
language = get_language_from_request(request)
return HttpResponse(f"Your language is {language}")
get_language_from_request() function.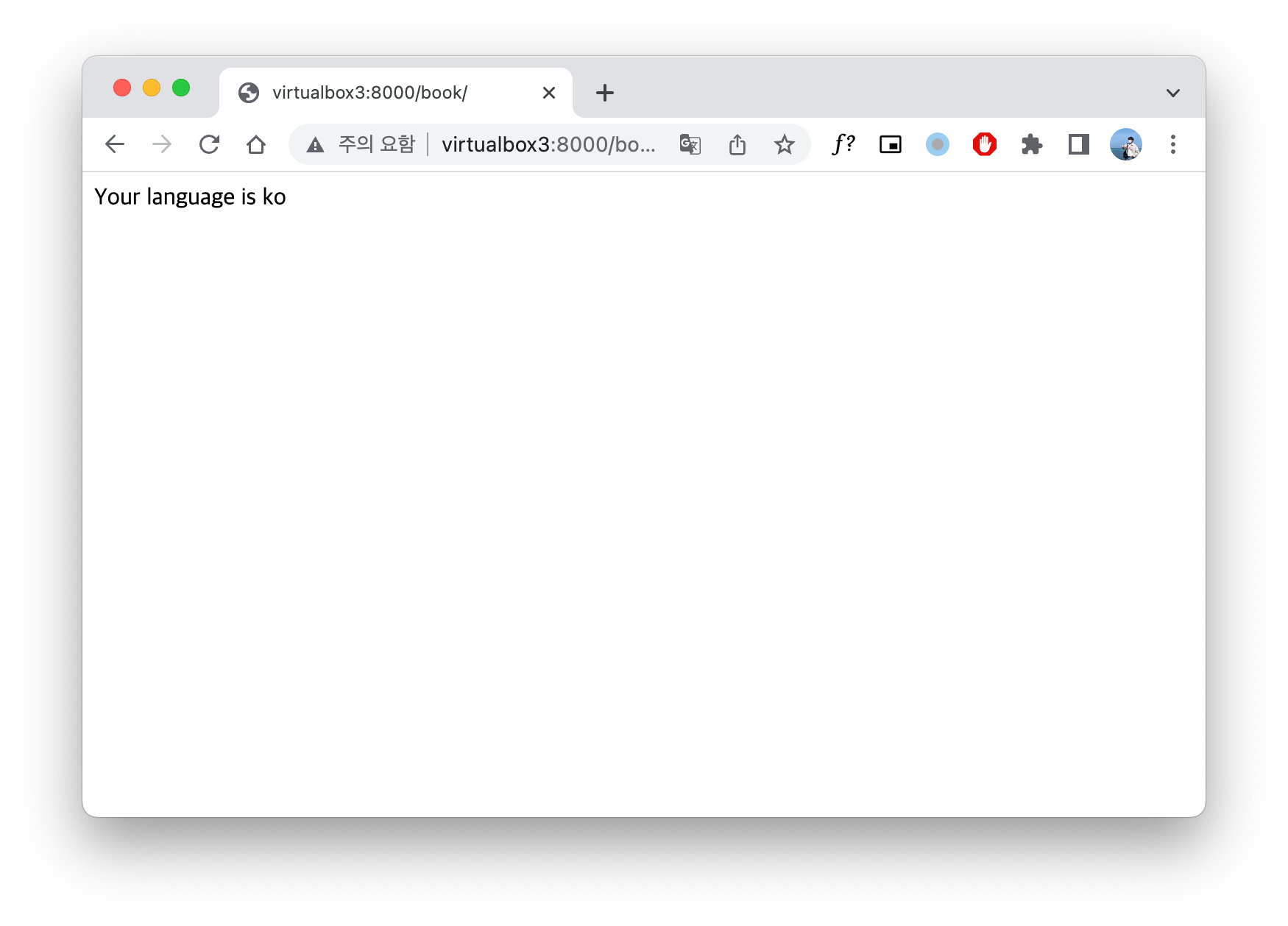
This is the raw request captured by Burp Suite to help your understand.
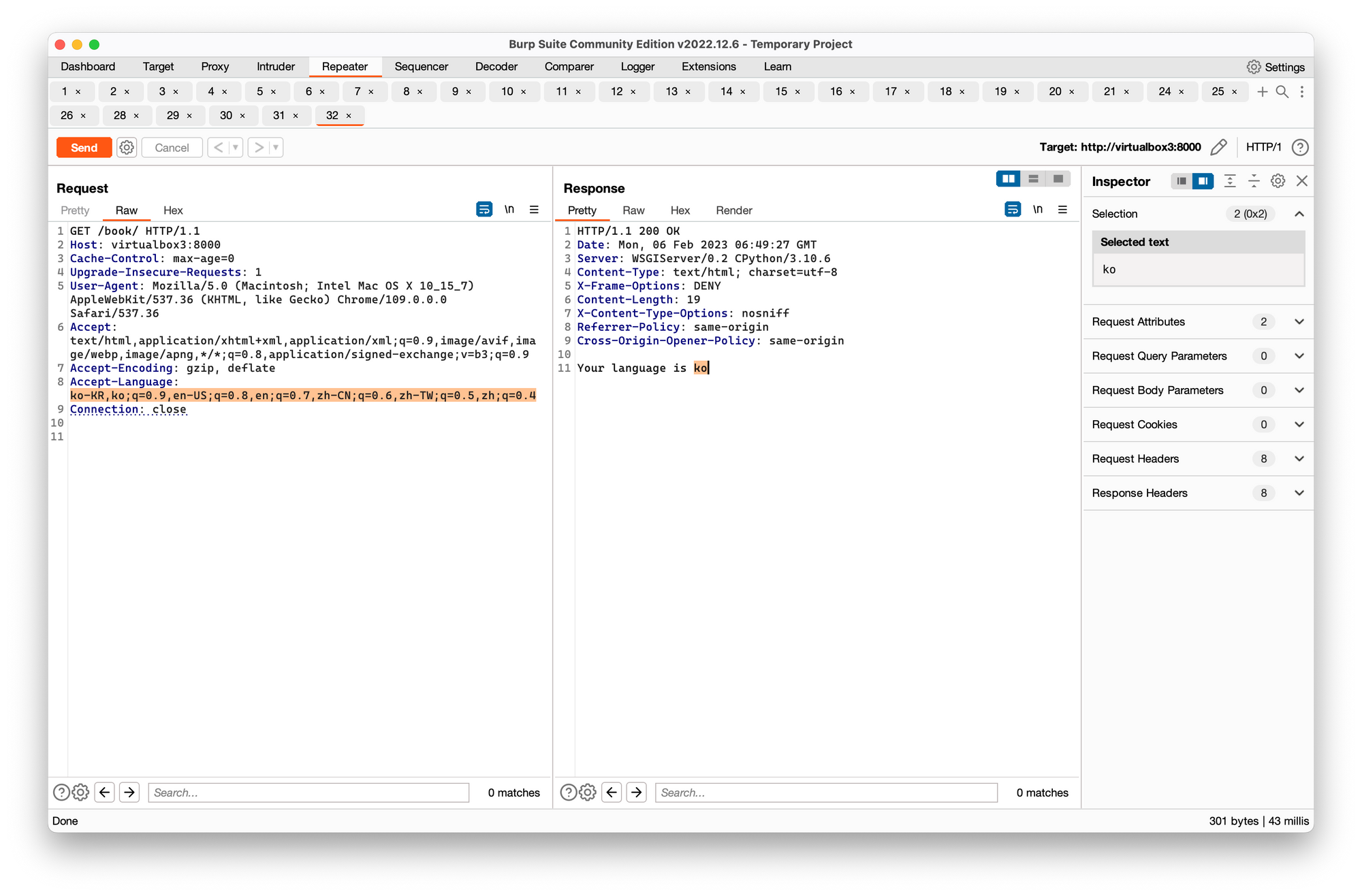
How was it implemented?
The function get_language_from_request() is defined as below.
def get_language_from_request(request, check_path=False):
# ...
accept = request.META.get("HTTP_ACCEPT_LANGUAGE", "")
for accept_lang, unused in parse_accept_lang_header(accept):
if accept_lang == "*":
break
if not language_code_re.search(accept_lang):
continue
try:
return get_supported_language_variant(accept_lang)
except LookupError:
continue
# ...This call the function parse_accept_lang_header() to parse Accept-Language header. We have to know how parse_accept_lang_header() function returns parsed language code. Let's see it.
accept_language_re = _lazy_re_compile(
r"""
# "en", "en-au", "x-y-z", "es-419", "*"
([A-Za-z]{1,8}(?:-[A-Za-z0-9]{1,8})*|\*)
# Optional "q=1.00", "q=0.8"
(?:\s*;\s*q=(0(?:\.[0-9]{,3})?|1(?:\.0{,3})?))?
# Multiple accepts per header.
(?:\s*,\s*|$)
""",
re.VERBOSE,
)
# ...
@functools.lru_cache(maxsize=1000)
def parse_accept_lang_header(lang_string):
result = []
pieces = accept_language_re.split(lang_string.lower())
if pieces[-1]:
return ()
for i in range(0, len(pieces) - 1, 3):
first, lang, priority = pieces[i : i + 3]
if first:
return ()
if priority:
priority = float(priority)
else:
priority = 1.0
result.append((lang, priority))
result.sort(key=lambda k: k[1], reverse=True)
return tuple(result)
It parses lang_string variable, which will be passed with Accept-Language header, by using regex. If you analyze the regex string to parse language, you can recognize that it allows the repetition of string which contains the character 'bar' (-). So you can send the payload below, as valid language code.
"xxxxxxxx" + "-xxxxxxxx" * 500This will take long time when you send the payload above at first time, but your second request will not take long because of functools.lru_cache(). It seems that the function parse_accept_lang_header() is safe from DoS attack.
Why is it vulnerable?
The built-in function functools.lru_cache() is a decorator that is used to cache the results of a function, so that subsequent calls to the same function with the same arguments can return the cached result, rather than re-computing it.
The maxsize variable as an argument of functools.lru_cache was given with 1000 when parse_accept_lang_header() is declared. So if I send the several long payloads aimed to attack regex in Accept-Language header, cache size of lru_cache will be exhausted quickly.
So eventually, your Django server was potentially vulnerable to DoS attack if you used get_language_from_request() or parse_accept_lang_header() in your server.
How was it patched?
ACCEPT_LANGUAGE_HEADER_MAX_LENGTH variable which seems like contant was added in head of file trans_real.py. The function parse_accept_lang_header() now becomes safe from DoS vulnerability by adding the mechanism which checks the length of the request clients send.
To see how developers of Django Project patched, see this commit history in Github.
 django
django

